数据挖掘建模:如何从数据中“淘金”?
本文笔者将对数据挖掘建模的一般过程进行解析,主要分为四部分:数据准备、模式发现、模型构建以及模型评价。

数据挖掘介绍
数据挖掘(Data Mining,DM): 就是从大量数据(包括文本)中挖掘出隐含的、未知的、对决策有潜在价值的关系、模式和趋势,并用这些知识和规则建立用于决策支持的模型,提供预测性决策支持的方法、工具和过程;是利用各种分析工具在海量数据中发现模型和数据之间关系的过程。这些模型和关系可以被企业用来分析风险、进行预测。
数据挖掘的目的就是从数据中“淘金”,就是从数据中获取智能的过程,数据挖掘是提供了从数据到价值的解决方案。
数据+工具+方法+目标+行动=价值。
目前,数据挖掘已有一系列应用:
- 分类分析:有监督学习,将数据映射到事先定义的群组或类。应用在将信用卡人分为低中高风险群等。
- 回归分析:用属性的历史数据预测未来趋势,应用预测哪些用户在未来半年会流失等。
- 聚类分析:无指导学习,在没有给定划分类的情况下,根据信息相似度进行信息聚类。应用在对客户行为分析,对客户分层进行精准营销。
- 关联分析:发现事物间的关联规则或称相关程度,常用在交叉销售,交叉分析,著名的啤酒与尿布。
- 时序模式:已知的数据预测未来的值,回归不强调数据间的先后顺序。
- 偏差分析:来发现与正常情况不同的异常和变化,并进一步分析这种变化是有意的诈骗行为,还是正常的变化。常用在防欺诈,以及保险领域。
以上这些应用涉及的技术和工具各不相同,然而却可以依据统一的方法论来实行,并可以协同作战,解决许多有价值的商业问题。
数据挖掘建模的一般过程
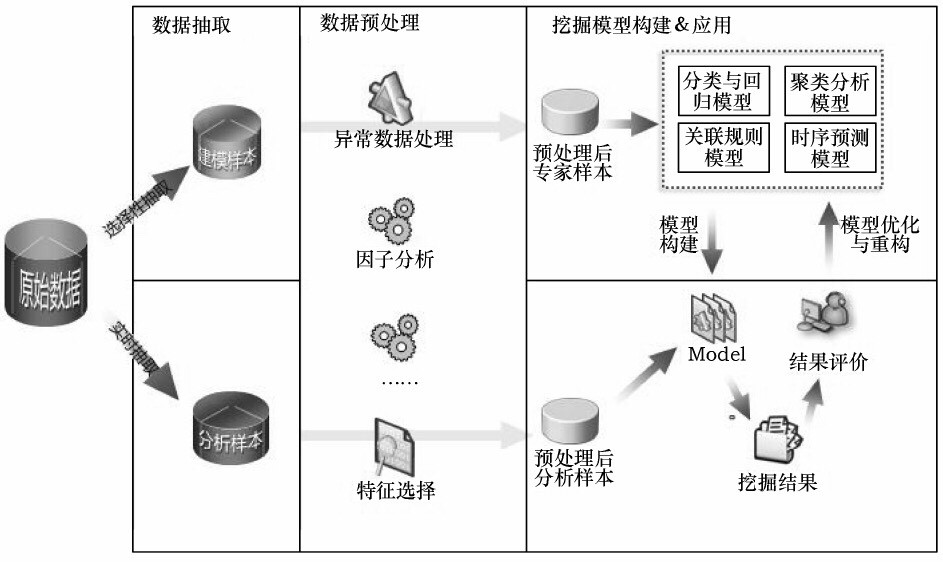
第一步,数据准备
数据选择主要考虑的包括:
- 哪些数据源可用?
- 哪些数据与当前挖掘目标相关?
- 如何保证取样数据的质量?
- 是否在足够范围内有代表性?
- 数据样本取多少合适?
- 如何分类(训练集、验证集、测试集)?
选择数据的标准,一是相关性,二是可靠性,三是最新性,而不是动用全部企业数据。通过数据样本的精选,不仅能减少数据处理量,节省系统资源,而且能通过数据的筛选,使想要反映的规律性更加突显出来。
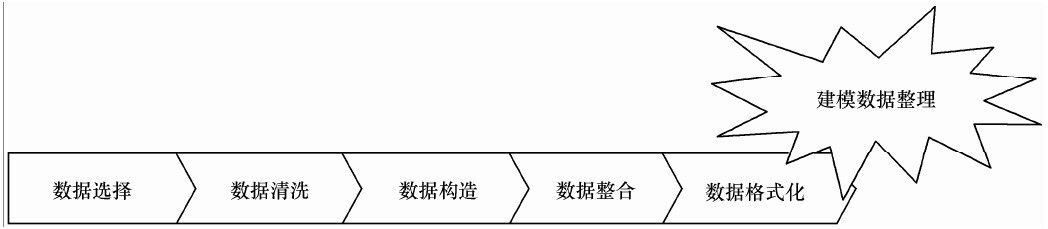
1)数据探索:数据清洗和构造
前面所叙述的数据选择,多少是带着人们对如何达到数据挖掘目的的先验认识进行操作的。
当我们拿到了一个样本数据集后,它是否达到我们原来设想的要求?其中有没有什么明显的规律和趋势?有没有出现从未设想过的数据状态?因素之间有什么相关性?它们可区分成怎样一些类别?这都是要首先探索的内容。
对所抽取的样本数据进行探索、审核和必要的加工处理,是保证预测质量所必需的。可以说,预测的质量不会超过抽取样本的质量。
数据探索主要包括:异常值分析、缺失值分析、相关分析、周期性分析、样本交叉验证等。
2)数据预处理:整合和格式化
当采样数据维度过大,如何进行降维处理?采样数据中的缺失值如何处理?这些都是数据预处理要解决的问题。
由于采样数据中常常包含许多含有噪声、不完整、甚至是不一致的数据。显然对数据挖掘所涉及的数据对象必须进行预处理。那么,如何对数据进行预处理以改善数据质量,并最终达到完善最终的数据挖掘结果的目的呢?
数据预处理主要包括以下内容:数据筛选、数据变量转换、缺失值处理、坏数据处理、数据标准化、主成分分析、属性选择、数据规约。
第二步,模式发现
样本抽取完成并经预处理后,接下来要考虑的问题是:本次建模属于数据挖掘应用中的哪类问题(分类、聚类、关联规则或者时序模式),选用哪种算法进行模型构建?
模型构建的前提是在样本数据集中发现模式,比如:关联规则、分类预测、聚类分析、时序模式等。
在目标进一步明确化的基础上,我们就可以按照问题的具体要求来重新审视已经采集的数据,看它是否适应挖掘目标的需要。
第三步, 模型构建
确定了本次建模所属的数据挖掘应用问题(分类、聚类、关联规则或者时序模式)后,还需考虑:具体应该采用什么算法,实施步骤是什么?
这一步是数据挖掘工作的核心环节,模型构建是对采样数据轨迹的概括,它反映的是采样数据内部结构的一般特征,并与该采样数据的具体结构基本吻合。
预测模型的构建通常包括模型建立、模型训练、模型验证和模型预测4个步骤,但根据不同的数据挖掘分类应用会有细微的变化。
第四步, 模型评价
模型评价的目的是什么?如何评价模型的效果?通过什么评价指标来衡量?
模型效果评价通常分两步:
第一步是:直接使用原来建立模型的样本数据来进行检验。
假如这一步都通不过,那么所建立的决策支持信息价值就不太大了。一般来说,在这一步应得到较好的评价。这说明你确实从这批数据样本中挖掘出了符合实际的规律性。
第一步通过后,第二步是:另外找一批数据,已知这些数据是反映客观实际的、规律性的。
业务应用场景:网红销售额评估模型、客户ROI评估模型、网红品类推荐模型、网红报价建议模型、网红欺诈行为预警模型、网红流失预警模型等
结论
实践表明:由于人工智能发展的局限性,计算机在未来相当长的一段时期内不可能像人类这样会进行复杂的思考,它只会按照人的指令工作。
但是,计算机拥有海量的数据存储能力和超强的计算能力,所以只要我们建立合适的业务模型,设计完善的执行程序,选择正确的分析算法,它一定可以更好地为我们服务。
数据挖掘技术是一个年轻且充满希望的研究领域,商业利益的强大驱动力将会不停地促进它的发展。
每年都有新的数据挖掘方法和模型问世,人们对它的研究正日益广泛和深入。尽管如此,数据挖掘技术仍然面临着许多问题和挑战:如数据挖掘方法的效率亟待提高,尤其是超大规模数据集中数据挖掘的效率;开发适应多数据类型、容噪的挖掘方法,以解决异质数据集的数据挖掘问题;动态数据和知识的数据挖掘;网络与分布式环境下的数据挖掘等。
另外,近年来短视频,图片等多媒体数据库发展很快,面向多媒体数据库的挖掘技术今后将成为研究开发的热点。
本文由 @无语凝咽 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: