数据分析体系(3):认清误区,避免过度“数据”
之所以选择数据这个专题作为第一篇,是因为我深信数据是基础的基础,是谈一切方法论的依据和根基所在。尽管相信数据是必须的,但我们也常常掉在数据的“坑”里。下面列举一些在工作中我曾遇到过的数据使用上的问题和错误,供大家参考。

一、为了数据而数据
您是否有过这样的体会,面对着海量的报表数据,一阵眼晕,顿觉无处着眼,每个字节似乎都在“跳动”,仿佛身处迷雾之中?反正我有,并且常常有(今日头条改名“字节跳动”,我脑海中浮出来的居然是这样的报表)。
报表上海量的数据往往“看上去好像有用”,或者某一次被用到过,就上了周报、月报。随着时间的推移,数据越堆越多,渐渐成为一片汪洋大海。这事实上也许没什么帮助。
首先,这会消耗数据团队的人力或技术资源来生成这些数据,消耗读者的大量时间精力来阅读这样的数据,然后往往并没有相应的产出。
其次,更糟糕的是,这样的“汪洋大海”会使真正值得被注意的数据彻底淹没,并得不到关注。数据太多了,大家往往干脆都不看,不是吗?
数据是拿来用的,不用的就是无用数据。建议如下:
1. 根据会实际执行的具体动作而定制数据需求。
2. 定期回顾数据报表,哪些很久没有被使用了,可以定期清理去除。当然,存档性的基础数据越全越好,但也应尽量减少数据冗余,以减低数据一致性风险。
二、幸存者偏差
统计学家亚布拉罕.沃德在二战中受聘于美军一个研究小组,从归航的幸存战机机身上残留的弹痕,倒推出被击落的战机的“致命部位”,找到战机的薄弱环节。下图是他的统计图:
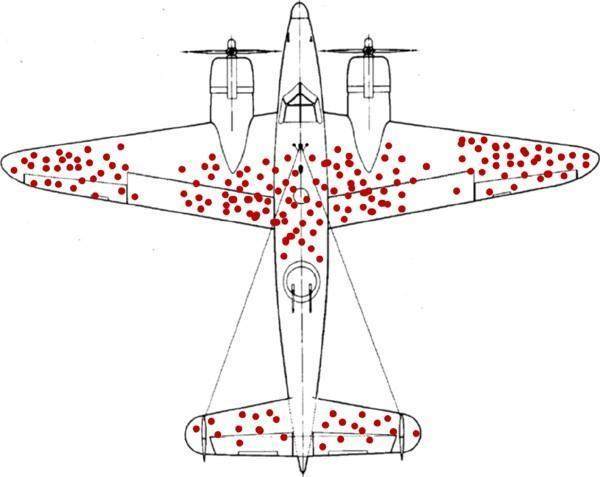
数据统计不会骗人,该图表明:应该在机翼和座舱前后加强防护能力。
然而,这结论真的对吗?请思考一分钟。
如前所述,以上的统计,主要是针对返航维修的战斗机所做的统计。而二战时期的战斗机,发动机和螺旋桨基本都在飞机的机头部位,我们应该可以想到,一旦飞机的心脏- 机头被击中,根本没机会返航,直接成了残骸,而残骸往往也很难定位被击中部位。统计图中机头没有红点,很容易错误地结论机头不需要额外加强,而这样的错误,代价是惨重的。
这就是“幸存者偏差”。该现象指的是只能看到经过某种筛选而产生的结果,而没有意识到筛选的过程,因此忽略了被筛选掉的关键信息。
实际的工作中我们也常遇到此类问题,例如:侧重局部数据分析,而统计局部选取不甚合理,与整体状况有较大差异,从而得出错误结论。或者,某品类转化较好,就结论其更符合消费者需求,而其实只是该品类获得了大部分资源。
三、过度反应于数据小幅波动
有时对环比做统计,看到流量增减了3%,就花很多时间去做分析,却得不出有价值结论。
这世界唯一永恒不变的就是变化。要对数据波动合理性有一个判断,超出什么幅度才代表可能会引起业务后果的异常状况(可以参考统计学相关知识),设立合适的警戒阈值,只有超出了上下限才触发一次分析。这样可以有效节省数据团队资源,也可以让自己专注于正确的事情。
建立数据波动警戒阈值时,建议考虑如下两点:
1. 充分参考历史数据情况,观察每一次引发数据波动的值得关注的“事件”带来对波动幅度,用统计学对方法确定警戒阈值。
2. 充分考虑正常时令因素或社会因素引起的波动,把这个波动带进去作为正常状态的基线,基线基础上进一步的超阈值波动才值得进行分析。
四、忽略趋势性数据
与上面提到的“过度反应”情况相反,有时小幅的数据持续性变化(同向的增减),可能在揭示着背后的某些必然性因素。如果观察到趋势性现象(连续5个或7个同向点,基于数据对应的事情本身有多关键),哪怕幅度微小,也应当引起重视,触发分析。详细参见本系列第一篇文章相关内容。
五、数据扭曲
很多时候数据受到多种未被统计到的因素影响而产生偏差。例如,下图是某互联网公司分析订单与用户自然流失关系的折线图。
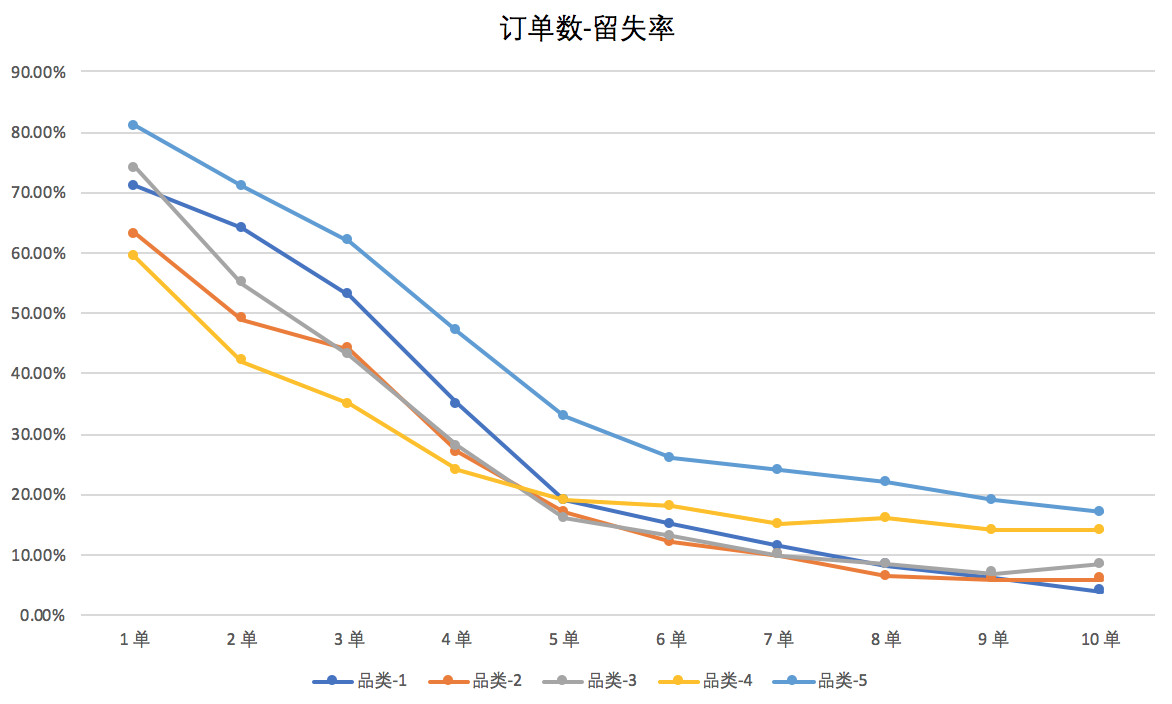
从上图不难看出,大致在4~6单之间流失率出现拐点,因品类而略有不同。于是,我们不难结论——第5单是留存的魔法数字。也就是说,如果用户下到第5单,留存会进入相对稳定的状态。于是,运营团队据此立项,通过每单补贴,或设定任务目标激励,推动用户从新客一路转化到5单。
大家先思考一下,这样做有什么问题?
可能您已经想到了,补贴激励如果投放力度过大,会直接推动用户产生非自然购买行为,或引发用户“薅羊毛”的操作,并且可能会引入大批黄牛党。而一旦到了5单,补贴结束,用户可能就会迅速流失,并没有如期望的那样形成对平台的深度认同和购买习惯。换句话说,用刺激手段给用户打“兴奋剂”后看到的并非自然行为,这也就造成了留存转折点的变化。我称之为数据扭曲,也就是外力作用下数据趋势发生了扭曲,并不能反应真相。
该怎么办在后面谈留存的时候再深入探讨。简单说,首先结合用户调研,深入理解该魔法数字背后的逻辑——往往是由于多次下单都有良好的体验,进而逐步形成了对平台的认同,并逐渐培养了在该平台(或其中某个品类)的购买习惯,进而稳定留存。
因此,补贴虽然能激励用户复购,却不能让补贴成为用户的购买主因,需要通过多元化的手段精细化结合小额补贴(如返京豆、淘金币)运营1转2,2转3……,让用户健康成长直至稳定。
六、过度分析
开发背景的同学可能知道一个设计上常见的错误:Over enginnering,中文可以翻译成“过度设计”。
意思是说,一个原本简单的功能设计得过于复杂,过度考虑了兼容性、扩展性或异常处理等因素,全无必要地增加了系统的复杂度、开发周期并可能降低系统的性能。就像为了防止万分之一的被高空坠物击中而每天穿着铠甲出门。数据的分析和运用,有时也会犯类似的错误。
先举一个管理学上的栗子:
多年前我带一个200多人的开发团队时,内部有大约30多个小组,当时我极其信奉量化管理(CMM第4级的核心),尝试推行一个全面的数据化绩效评估体系,来考评各组的工作成效。
初期我考虑了代码行数,bug数,按时交付情况,测试通过功能点数量等几个核心因素,并结合SQA团队做出的第一个版本在组长会议上进行探讨。
一石激起千层浪。立刻有组长提意见,说各组开发模块的复杂度不同,影响代码质量和速度,因此我把复杂度作为加权系数乘了进去,于是大家一通争执到底乘几合适……
好不容易摆平了,又有组长提意见,说有的代码是开发工具自动生成的,于是又把这个参数加入评估模型……
接着又有组长提意见,说有的组受客户需求变更影响特别严重,要被考虑,于是……
再接着又有组长提意见,说自己组的代码模块是接手的,要修里面问题,和新模块开发的难度不能比……
于是,改了几十遍的绩效模型变得庞大复杂。
尽管如此,大家好像也还不怎么服气,因为还有更多因素没涵盖,而且乘以的各种权重,争议都很大……
您可能看到问题了。虽然管理学不在本文范围,但这同时也是一个过度使用数据的例子。
再举另一个例子——做计划。
有的公司做计划十分粗放,随便拍一个,执行的时候再说。但另一个极端是,过度计划。
例如,预测明年的销售,于是要分析明年的流量、商品、价格、转化;然后对每个因素继续深入分析,比如流量,要考虑市场宣传、渠道、拉新活动、会员、产品和运营的动作,等等。然后每一个因素,又继续往下细分……到最后一层不能拆了,就拍个数。看起来好像比前一种合理,对吗?
结果是做计划消耗了巨大的人力,在小细节上反复掂量,而忽略了很多未代入因素会产生更重大影响。比如国家经济形式、工商政策、关税、行业趋势、竞争对手动作……这些因素根本无法准确预测,也无法纳入量化分析。
此外,计划做得再精细,分解得再到位,最底层数据也是“拍脑袋”拍出来的,拍脑袋数据汇总起来也还是拍脑袋数据,虽然看起来比不分解直接拍更合理有逻辑,但并不存在绝对客观的预测和计划。
我很相信计划的两面性—— 一半是事先分析做出来的,一半是在执行上管出来的 。
两手抓,两手都要硬。分析出商业目标的核心影响因素,根据同比状况和商业需要做第一层最多到第二层分解,然后作为指标下达到各个部门,随后以强有力的管理来推进,通过不断的资源调整来纠偏,明确奖惩,杜绝借口,并在必要时根据实际情况对计划做出调整。
当然,数据分析和使用,什么度是最适宜的,这个可能需要结合自己的最佳判断来给出。但牢记关键——抓核心放次要,保持全局视野,勿过度陷入细节。
最后推荐一下数据分析的书。
多年前我学习数据分析的时候读过一本书《网站分析实战》,在建立数据思维和实用角度上,从概念到实操都极具参考意义。

数据分析这个专题到这里先告一段落,感谢大家的耐心阅读,希望有所帮助。
最后声明一下,所有我的文章仅代表我个人观点,仅供学术交流探讨。
作者:徐霄鹏,微信公众号:产品遇上运营。亚马逊高级总监,产品、中央运营及增长团队负责人,前京东、携程高级产品总监。精通前台产品、运营及用户增长等领域。
本文由@产品遇上运营 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自@Unsplash, 基于CC0协议
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: