纽约蹭饭手册:怎样利用自动化脚本在纽约省钱又省心?
你有没有想过“霸王餐”也可以光明正大地吃,甚至吃得合法合理呢?或者很多人都会说不可能做到,但是笔者向我们证明了——技术就是力量,可以用技术吃一次冠冕堂皇的“霸王餐”。

在家做饭不下馆子可以减少开支已经是公开的秘密。但作为一名美食天堂的国民,不下馆子几乎是不可能的。
到处都是火锅店、烧烤餐厅或美味披萨店,瞅一眼这些美食,就足以摧毁大家省钱的意志力。如果你即不想让钱包当成受害者,又不想放弃美妙的用餐体验,就得自己“造”钱来支付饭费。
来,跟随作者的脚步,让你走上了各种中餐、西餐、中西餐的蹭饭之路。
首先我们的目标是到最棒的餐厅吃到霸王餐。这是个技术活,达成这个目标有两种方法:要么让代码做这件事,要么有大量的空闲时间。
本文会简要介绍一下使用的技术和编程语言,但不会给出代码或相关内容。会解释怎样使用逻辑回归,随机森林,AWS和自动化脚本,但都不会深入。本文更多的是理论而非实践。
如果你是一个非技术人,这篇文章仍然适合你,只不过要多花费一点时间和精力。文章里的这些方法大部分都很枯燥,这就是为什么我要用自动化脚本来实现它们的原因。
走起,我将从结果开始,然后解释我是如何做到的。
一、我做了什么
在今天这个数字时代,Instagram用户数是一种财富。像传闻说的那样可以通过大量的粉丝来赚钱,或者对我来说,用粉丝来支付我的饭费,这就是我所做的。
我创建了Instagram个人首页,展示纽约的轮廓、标志性景点、优雅摩天大楼的图片等等。这使我在纽约地区积累了超过25,000名粉丝,并且仍在快速增长。
我通过Instagram发消息或电子邮件联系当地的餐馆,用在主页上向粉丝发布评论来换取免费餐或至少是用餐折扣。
几乎所有我联系的餐馆都给了我免费试吃的机会或优惠卡。大多数餐馆都有市场营销预算,所以他们很乐意为我提供免费的用餐体验,以便开展促销活动。有时优惠太多我只好送一些给朋友和家人。
这本来没什么稀奇,关键在于我将整个过程自动化了,我的意思是100%不用手动操作了。我编写的代码可以自动找到图片或视频、制作标题、添加主题标签、标记图片或视频出自哪里,还能过滤垃圾邮件、发帖、关注用户和取消关注、点赞、监控我的收件箱,最重要的是自动向与可能需要促销的餐馆发消息和电子邮件。
自从有了这套代码,我甚至都不需要真正登录该帐户,根本不用花时间在这上面。它本质上是一个机器人,但普通人无法分辨,因为它的行为和人一样。作为它的开发者,我可以坐下来欣赏它(和我的)工作。
二、我是怎么做到的
我会带你从头到底了解我在这个过程中所做的每一件事。其中一些事看似常识,但当你用自动化系统来完成这些事的时候,细节就变得很重要。该过程可分为三个阶段:内容共享,黑客式增长以及销售和促销。
1. 内容共享
其实,我的帐户所发布的内容都不是我原创的,而是我重新分享其他人的内容,但有注明来源。如果有人说我侵权,要我撤下他们的照片,我会马上照做。但因为我在分享里带了他们的主页的链接,所以他们从来都只有感激我。
每天多次发布内容是必须的。这是Instagram算法确定你的曝光度的主要因素之一(通过“探索页面”)。每天发帖,特别是在每天“高峰时段”发帖,非常单调乏味。大多数人做了几周就会放弃,甚至有时一两天漏发也会导致曝光度下降。因此,将内容收集和分享过程自动化是很有必要的。
(1)获取图片和视频
我最初考虑用爬虫从Google图片或社交新闻站点Reddit上抓取图片。我遇到的最大的困难之一就是Instagram对所发布图片的大小有特别要求,最好是“方形”图片,也就是宽度等于高度,因此发布非正方形的图片会被拒绝。这使得检索图片变得非常艰巨。
我最终决定直接从其他Instagram帖子中搜索,因为图片大小符合要求,而且还可以准确知道其来源,这一点在自动化脚本里非常有用。
我收集了50个Instagram帐户,这些帐户发布了许多关于纽约的优质图片。我用开源软件编写了一个爬虫来下载这些帐户上传的帖子。除了下载文字内容外,还有图片和一堆元数据,如标题、点赞数和位置等。我将爬虫设置为每天凌晨3点或当我的图片库为空时运行。
这样,我把所有内容都集中存储在一个地方,包含正确格式的各种内容。
(2)自动确定什么是“好”或“坏”的内容
并非所有在Instagram上发布的内容都值得重新分享。有很多卖东西的帖子,骂人的贴子,或者有些内容跟我想要的不相关。以下面这两篇帖子为例:
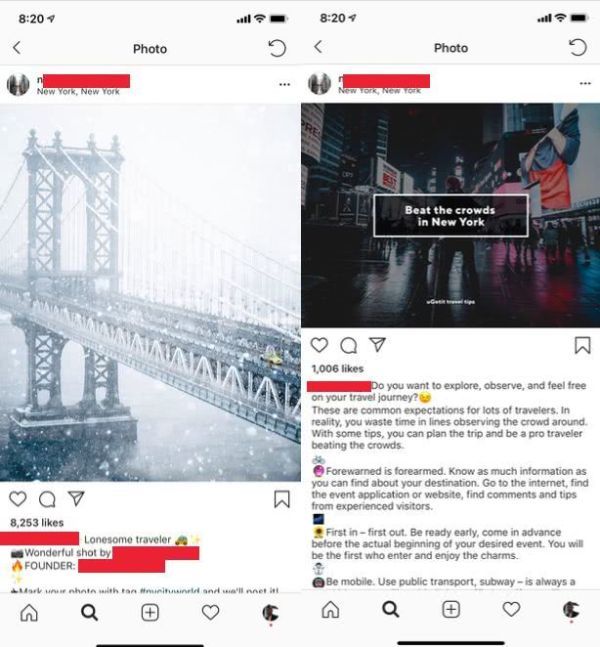
这两个帖子来自同一个纽约的Instagram帐户。左边帖子发布的是自然风光,我很乐意把它重新分享在我的主页。右边的广告没有任何上下文,标题分两行,这实际上是在给一个纽约的手机应用打广告。
如果我把它放在我的主页上,那会就显得让人困扰,与我的主页显得格格不入。你可以看到点赞数量的差异-8200对1000。我需要脚本能够自动过滤掉右边的帖子,并重新分享左边的帖子。
因此,我不能盲目地重新分享我提取到的所有内容。但我又希望这是一个自动化过程。所以我需要创建一个算法,可以取其精华去其糟粕。
1)算法的第一部分包括一些hard-coded规则,第二部分是机器学习模型。
A. 算法的第一部分——hard-coded规则
我做的第一件事是根据元数据中的特定规则优化我的inventory。在这个过程中,我必须保持严谨。如果出现了一个警告,那么图片就废了。
理论上,我可以抓取到很多内容,但如果算法在我的页面上发布了不合适的内容,那么在我发现之前可能已经有很多人看到了。
我接下来要做的是看看评论是否不可用。我的经验是,不可用的评论大多与有争议的帖子有关,并不值得我冒这个风险。
我要做的最后一件事是看图片中是否标记了多个人。很多时候,图片中的一个标签是标记它来自哪里,这实际上是有用的。但是如果图片有多个标签,那么就会出现混淆。
根据这些规则,我可以排除大部分垃圾帖子和不受欢迎的帖子。然而,不能仅仅依据是否推销东西来判断一篇帖子是否具有高质量内容。此外,我的hard- coded规则可能仍然会遗漏一些销售类的广告帖子,因此我想在完成第一部分后再过一个二级模型。
B. 算法的第二部分——机器学习模型
经过第一部分算法过滤——hard-coded规则,我发现仍然存在一些垃圾帖子。我不打算人工手动剔除它们,我计划将这个过程完全自动化。
每个帖子上都有大量的元数据,包括点赞数,标题,发布时间等等。我最初的目的是尝试预测哪些图片会获得最多的点赞。然而,很明显,网红博主自然会获得更多的点赞,所以这不能作为准确的判断依据。
后来我的想法是让响应变量等同于点赞率(即点赞数/粉丝数),并尝试进行预测。但在观察每张图片及其点赞率后,我认为点赞率和图片质量的相关性不大。我不认为那些点赞率高的照片就是高质量照片。
一些不知名的摄影师发布的图片内容并不一定比网红博主差,即便网红拥有更高点赞率。我决定用分类模型替换回归模型来评价图片内容的质量,判断其是否可以发布——一个简单的是或否问题。
在查看其他元数据之前,我抓取了大量照片并把每张照片手工标记为0(差)或1(好)。这是非常主观的判断,可以说我是根据自己的主观判断制作模型。但我认为我的判断应该和大部分人一样。
我生成了数据集。响应变量为0或1(即差或好),具有许多特征。每篇帖子的元数据可以提供我以下信息:
从这七个解释变量里,我改变了一些我认为有用的特征。例如,我改变了评论的数量和点赞率。我从标题中提取了带“#”号的标签的数量,并将其作为column,并对标题中提到的用户数量进行了相同的操作。
我对其余的标题进行向量化,用于后续的自然语言处理。向量化是删除外围词(如“the”,“and”),并将剩余词转换为可以用于数学分析的数字字段。我得到了以下数据:
我使用了许多分类算法,例如支持向量机(Support Vector Machines)和随机森林树(Random Forests),但最终是采用了简单的逻辑回归算法(Logistic Regression)。
我认为有时候最简单的答案就是正确的答案。无论我采用哪种方式处理数据,逻辑回归算法在我的测试集上都表现最好。
与其他分类算法不同,我可以在进行预测时设置阈值的得分(threshold score)。分类算法通常输出二进制类(在我的算法里是0或1),但Logistic Regression实际上会输出0到1之间的小数。
例如,它可能将帖子评为0.83或0.12。人们通常将阈值设置为0.5,并将所有大于0.5的定为1,其余的定为0,但这取决于具体使用的案例。这个过程很关键,所以我将我的阈值设为0.9,并低于该基准的内容视作无用的。
在部署我的模型之后,图片和视频首先经过一套严格的规则清理,然后再经过Logistic Regression筛选出优秀的素材。现在我能够继续为每个帖子添加说明和打分。
2)自动化说明和打分
我现在有一个自动收集相关内容并删除垃圾图像的系统——但我还没有完成。
如果你之前用过Instagram,那么你应该知道每个帖子的图片或视频下方都有文字说明。但因为我实际上看不到这些图片,也没有时间给它们全部加上说明,所以我需要制作一个通用标题。
我做的第一件事是制作最终模板。接着我要将代码填进去。让我们一个个来看怎么填。
A. 标题
我创建了一个文本文件,其中包含许多预定义的通用标题,可以匹配任何的图片。这些标题可以是关于纽约的名言、通用问题或是简单的赞美。
对于每个帖子,标题是随机选择的。我有许多备选的标题,根本不用担心某个标题会频繁出现。对于我们的例子,我们可以选择 “Who can name this spot?”。
B. 来源标记
自动标记图片资源的来源可不是件容易的事情。通常情况下,一个Instagram账号页面上的图片并不代表这账号拥有图片的版权。这样的账号可能也是重新分享的内容,会在页面的标题中或图片标签里标记图片来源。
对此,我决定无论如何先标注上图片的第一来源;如果我可以根据其他信息找出到图片的原始出处,那么我就继续在后面添加。通过这种方法,我基本上就可以标志出所有图片素材了。
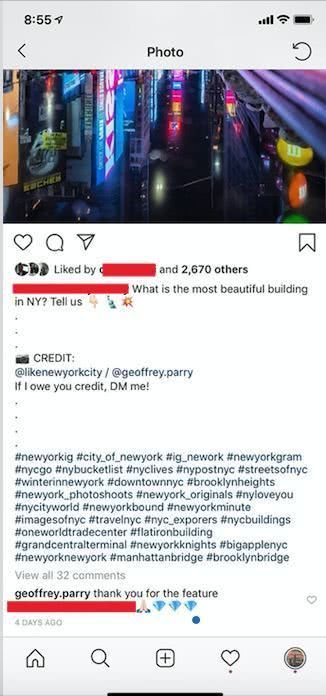
首先我们看一下@likenewyorkcity的这个帖子,尽管是这个账号分享出了这张图片,但图片中的标签和页面标题上@geoffrey.parry才是图片的真正版权拥有者。

理论上我希望我的代码可以在识别这张图片后得出这样一条输出:
第一步很简单,我只需要直接标注出出现的账号即可,但第二步就没那么容易了。
我通过REGEX(正则表达式工具)匹配一些类似于“by”或者“photo”的关键词,然后找到紧跟在关键词后的“@”标识,通过这种方法抓取的用户名便被我标注成图片来源的第二部分。
如果标题中没有出现这些关键词,我便检查是否有人为图片打了标签,这些打了标签的账号便被我“默认”为我该标注出的对象了。尽管这种简单粗暴的方法并不是那么完美,但至少比不这么“默认”强上好几倍,不失为一种值得尝试的方法。
我总是能精准地标注出图片的正确来源。实际上,人们还多次在我的图片下评论道“感谢分享!”(接下来展示出的图片便是一个很好的例子)
C. 标签
Instagram允许用户为图片打上30个主题标签,图片便会在相应的主题下展示。于是我创建了一个包含100多个相关主题的文件:
刚开始我每次都会随机在其中选择30个主题,而且不久后,我可以根据实际结果比较出哪些主题标签会得到更多“赞”。
D. 模板填充
经过以上这三个步骤后,我便可以将采集到的信息填充到最后的模板中,为每一个帖子“量身定制”标题。
下面是最终的产出成果:
最后成功如下:

我使用适合纽约市的任何图片的通用标题,标记了图片的Instagram帐户和原始来源,添加了三十个主题标签来提升帖子的曝光率。如果你继续查看帖子评论,你甚至还可以看到原始作者向我表示感谢。
E. 发布
现在我有一个集中管理的图片资源库,并可以使得每个帖子自动化生成标题,仅需最后的临门一脚——发布。
我在AWS上启动了一个EC2实例来托管我的代码,之所以选择这种方式是因为它比我的个人计算机更可靠——它始终保持联网状态,而且项目的工作量完全包含在AWS免费服务的条件限制之下。
我编写了一个Python脚本随机抓取其中一张图片,并在完成抓取和清理过程后自动生成标题。我设置了一个定时任务:每天早上8点,下午2点和晚上7:30调取我的API,完成所有的发布操作。
此时,我已经完全自动化了内容查找和发布过程,我不再需要每天都找资源和发帖子运营我的账号了——程序为我完成了所有事情。
2. 黑客增长
涨粉
仅仅发布是不够的——我需要制定一些方法持续涨粉。由于我不会手动执行任何操作,因此这一步骤我也需要想办法自动化处理。我的想法是通过直接与受众的兴趣用户直接互动以增加账号的曝光率。
我写的交互脚本从美国东部时间上午10点到下午7点运行,在我看来这段时间是Instagram最活跃的时间范围。在这一天中,我的帐户有条不紊地关注,取关,并为相关的用户和照片点赞,以使他们以同样的方式与我互动。
关注(更加数据科学的方式)
如果你是Instagram用户,不管你是否意识得到,我敢肯定都被“卷”过这种增粉方法,尤其对于试图增加粉丝的用户来说非常有用。某天如果你在健身版块中关注一个有趣的Instagram页面,第二天你就会被一群健美运动员和健身模特所关注。尽管这种方法看起来非常微不足道,但它确实非常有效。
需要注意的是你不能在Instagram上滥用这个方法关注其他账号。Instagram的算法有非常严格的限定,如果你在一天内操作过多或关注太多用户,他们会将你停止你的操作甚至封掉你的帐号。
此外,你一天在Instagram上最多只可以被7500人关注;而且经过大量的测试,我发现你可以在一天内关注400人,取关400人。毕竟操作条件有限,每一次关注都非常宝贵,不能浪费在不太可能和你互粉的人身上。于是,我决定采集每次操作的元数据,基于此建立一个模型来预测某个人与你互粉的可能性,确保我的每一个关注操作都是有意义的。
我花了几分钟手动收集了20多个与我处在版块下的帐号。我没有初始数据,因此前几周我为增加我的关注量随机执行这些操作,但更重要的是我需要采集尽可能多的元数据,以便我可以建立我的预测模型。
我浏览了20多个相关帐户,关注了他们的粉丝,赞他们的照片或评论他们的帖子。在每次关注操作中,我都尽可能多地获取用户的元数据形成一个CSV文件,包含他们的关注者和粉丝的比例,他们是公开账号或私人账号,或者他们是否有个人资料图片等。
每天,脚本都会自动扫描CSV文件并标记他们的反应,通过0,1,2进行顺序评级。如果两天内用户没有任何回应则标注为0,如果用户回粉但没有在最近的十张图片中发生任何互动行为则标注为1,2则是最理想的结果,表示他们回粉并在最近十个帖子中进行了互动。这样下来,我的数据集看起来便是这个样子的:
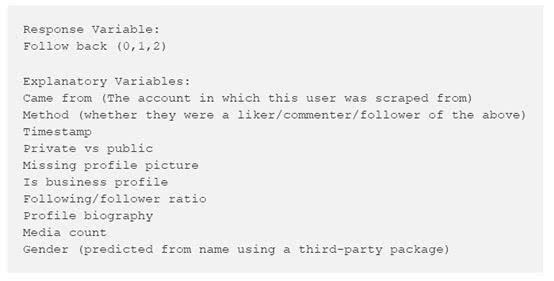
在将数据“喂”进ML模型前,我通过探索性数据分析得出以下结论:
- 虽然点赞党和评论党较关注党回粉我的可能性小,但他们更喜欢与我互动。这说明尽管他们无法直观地带来关注量的增加,但他们可以提升我账号的质量。
- 早上关注用户比晚上关注用户的回粉效果好。
- 公开的账号较私密账号更愿与我互粉。
- 女性较男性更愿意回粉我的账号。
- 关注用户数大于粉丝数的用户(关注与粉丝的比例大于1.0)更愿意与我互粉。
从上面的洞察,我优化了最初对搜索用户的方式。我调整了我的设置,只在早上去关注,主要寻找女性用户。现在,我终于能够建立一个机器学习模型,在与用户交互之前,根据用户的元数据预测是否会关注我,这样就不会浪费我每天能够关注的用户额度,去关注一个不会跟我互粉的人。
接下来,我选择使用随机森林算法对后续的结果进行分类。最初,我并没有设置结构或结果变量,而是使用了许多不同的决策树,因为我想得到它们的可视流程图。随机森林是决策树的增强,纠正单个树中存在的不一致性。在对我的训练数据进行建模后,测试数据上的精度一直超过80%,所以这对我来说是一个非常有效的模型。进一步,将模型应用于抓取的用户的代码,优化了关注算法,我的关注人数开始蹭蹭的往上涨。
取关
两天后,我就不会再继续关注我之前关注的人,两天已经足够让我确定他们是否会回粉。这样我能关注更多的人、收集更多的数据,并持续涨粉。
为什么我要对他们取关呢?有两个原因:第一,我的关注人数的额度上限为7500人;第二,每个人肯定都希望提高被关注/关注的比率,这样才能体现自己特别受欢迎,特别吸引人。
这是一项简单的任务,因为你不需要做出任何决定。你某一天关注了400个人,两天后你把这些人取关就行了。
点赞
点赞也可以提高关注人数。但是我没有投入太多的精力去选择一些大家都喜欢并且会去点赞的图片贴在我的账户中,因为对比以上其他方法,这个效果并不那么明显。所以,我只是提供了一组预定义的主题标签,通过主题关联,用户的连锁点击,收获一些关注者。
3. 自动推销
至此,我有一个特别智能的Instagram机器人。我的NYC主页会寻找与它相关的内容,淘汰不良的潜在帖子,吸引用户群,并全天发帖。此外,从上午7:00 到下午 10:00,它通过分析点赞、关注和不关注的受众人群来修改自身的设置,并且通过一些算法来优化受众人群的定义。最棒的是,它的分析与操作更加人性化,与Instagram真实用户相似。
有一两个月,我能明显看到关注人数的增长。每天我的账户中都会多100到500名的新关注者,一起欣赏我所爱的城市的美丽图像。
我可以开始享受我的生活,认真的工作,和朋友出去吃饭、看电影,并不需要花费时间去手动发帖。当我忙于自己的事时,它能完全托管我的账户。
当我拥有了20000个追随者的时候,我决定是时候靠它来蹭吃蹭喝了,所以我需要它自动推销我的产品。
我做了一个通用的消息模板,无论是餐馆、剧院、博物馆还是商店,这个模板都能适用。下面就是我绞尽脑汁想出来了的:
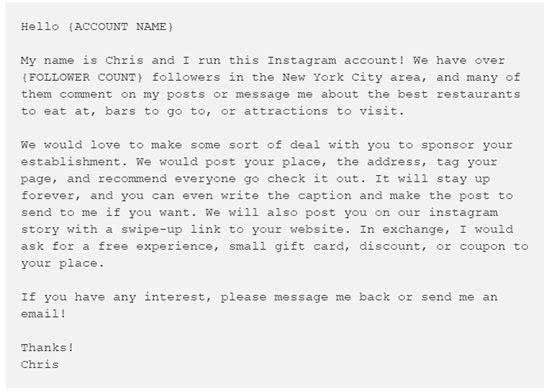
现在,我只需要记录账户名称和消息发送时我的关注者数量。
我的目标是找到商业用户并像他们推销我的产品。商业用户资料与普通用户资料略有不同—商业用户可以在其网页上添加电子邮件、电话号码、地址等其他详细资料。但最重要的是,他们的资料中都有一个类别标签。

上面那张图中是一个商业用户的示例。在左上角的名称下方,显示出它是一个韩国餐厅,同时顶部设有电话呼入、电子邮件和地址等提示信息。
我写了一个Python脚本来查找这类页面并且让我的帐户能够自动向它们发送消息。该脚本采用两个参数,一个初始主题标签和一个要在类别标签中查找的字符串。这里,我使用标签“Manhattan”和字符串“restaurant”来举例说明。
这个脚本的作用是去提取主题标签并加载照片,然后遍历这些帖子,直到找到在照片中标记用户的帖子。如果找了到,它会检查其标签,确认它是否是商业用户。
如果是,就查看该用户类别。如果类别包含“餐馆”一词,则会向他们发送我的信息。商业用户一般都会在他们的页面上留下他们的电子邮件,所以可以向他们自动发送电子邮件,在后台跟进我的Instagram消息即可。在搜索过程中,我可以随时将标签更改为#TimesSquare,也可以将目标字符串更改为“博物馆”等,我想搜索什么都行。
当我登录进入账户后,我会看到它自动生成和发送的消息。
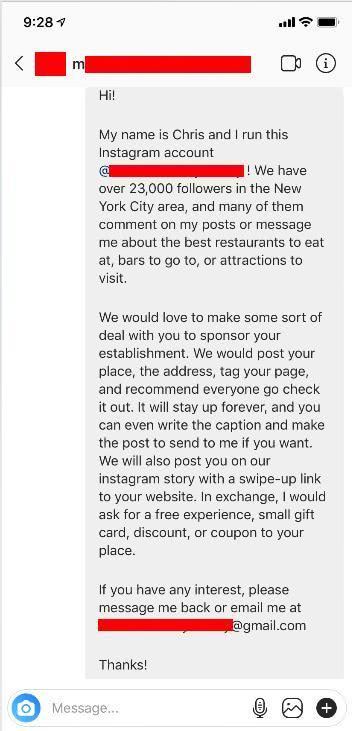
如果我去我的Gmail发件箱, 我就会看到以下邮件:
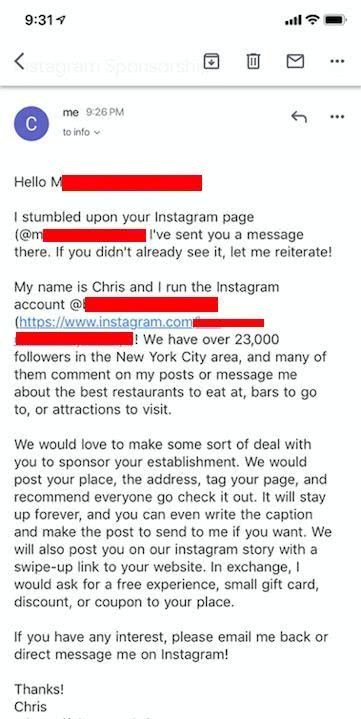
我还有一个脚本, 用来监测我的收件箱中的任何回复,同时提醒我。如果我收到回复邮件,我就会联系我的潜在客户。
以上这些操作,都是脚本自动运行的, 并不需要任何人工操作。
我终于实现了蹭吃蹭喝~
最终效果比我之前想象的还要好,我利用Instagram推广换取了很多餐厅的礼品卡以及免费餐。
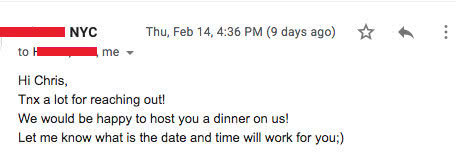
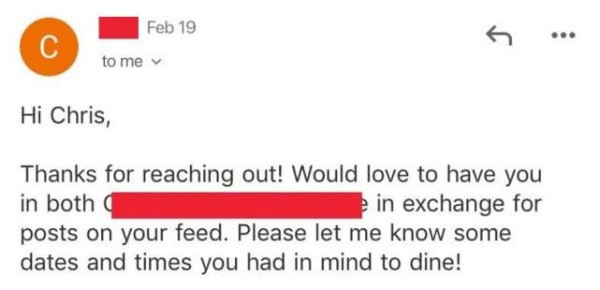
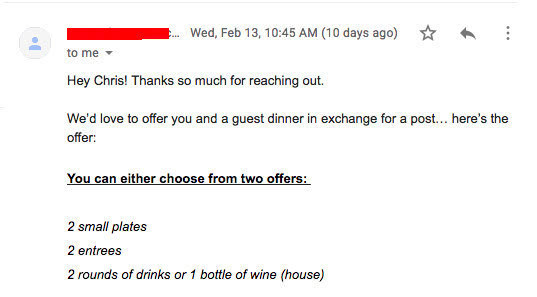
借助人工智能、自动化脚本和数据科学的力量,在代码脚本自动运转时,我可以高枕无忧。它是一个特别尽责的推销员,让我能够有自己的时间享受生活。
作者:Chris Buetti,NBC环球的数据工程师,2017年毕业于维克森林大学。
本文由 @CDA数据分析师 翻译发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: