人工智能行业研究报告
“人工智能就像一列火车,它临近时你听到了轰隆隆的声音,你在不断期待着它的到来。它终于到了,一闪而过,随后便远远地把你抛在身后。”
“人工智能已经来了,而且就在我们的身边,几乎无处不在。”

一、什么是人工智能
人工智能(Artificial Intelligence),英文缩写为AI,是达特茅斯大学助理教授John McCarthy在1956年提出的。但是,对于人工智能的定义一直没有统一的观点,不同的学者和研究人员根据不同的语境和关注的角度提出了多种对于人工智能的定义。
笔者根据多年的投资经验以及对人工智能项目的实地尽调,认为人工智能是指使用机器代替人类实现认知、识别、分析、决策等功能,其本质是对人的意识与思维的信息过程的模拟。 而我们在衡量人工智能能力的时候,必然涉及到三方面的能力, 即计算能力、感知能力、认知能力。
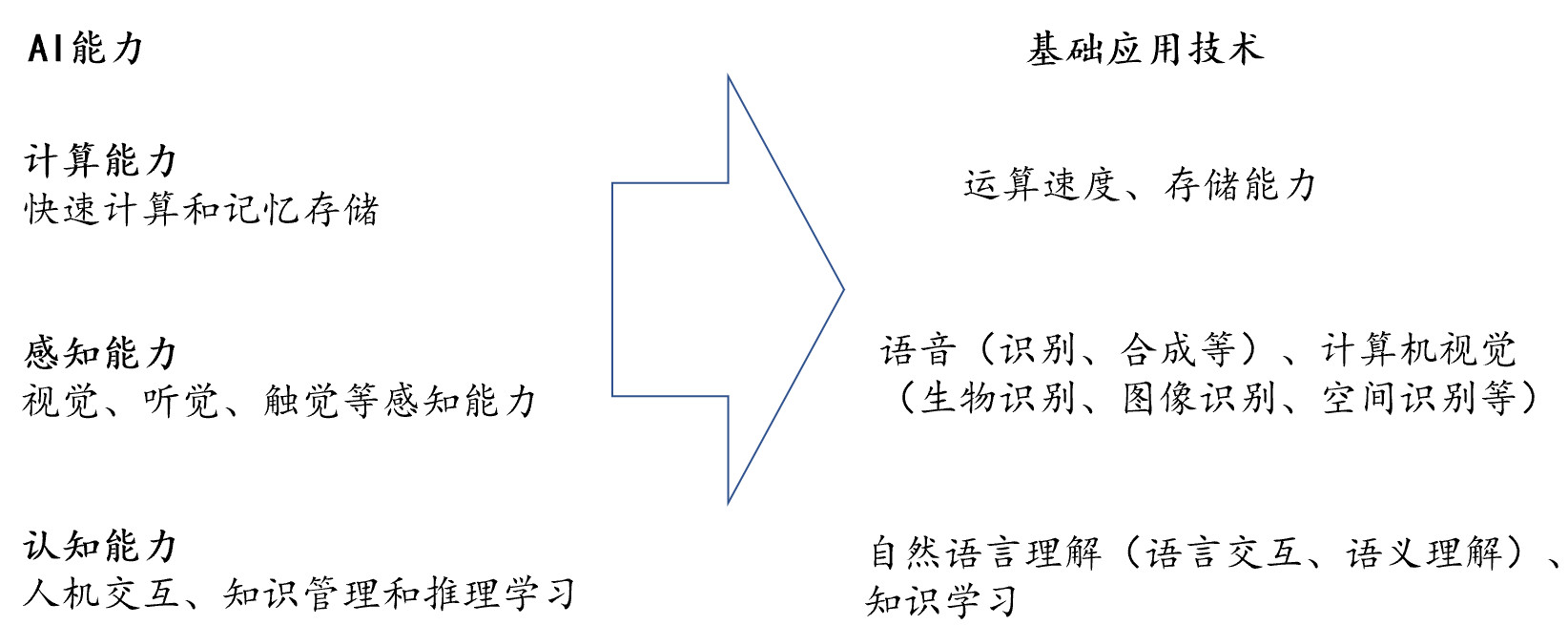
其中,计算能力是指机器快速计算和记忆存储能力。在计算能力方面,计算机已远远超过人类的计算和存储能力;感知能力,是解决机器听到看到问题,一般指视觉、听觉、触觉等感知能力,在技术层面,一般认为语音识别、图像识别等技术属于感知智能的领域;认知能力,解决机器听懂看懂的问题,通俗讲是“能理解、会思考”。
二、国内AI市场概况
(1)技术层面,计算机视觉是当前热点,芯片和算法等底层会是未来方向
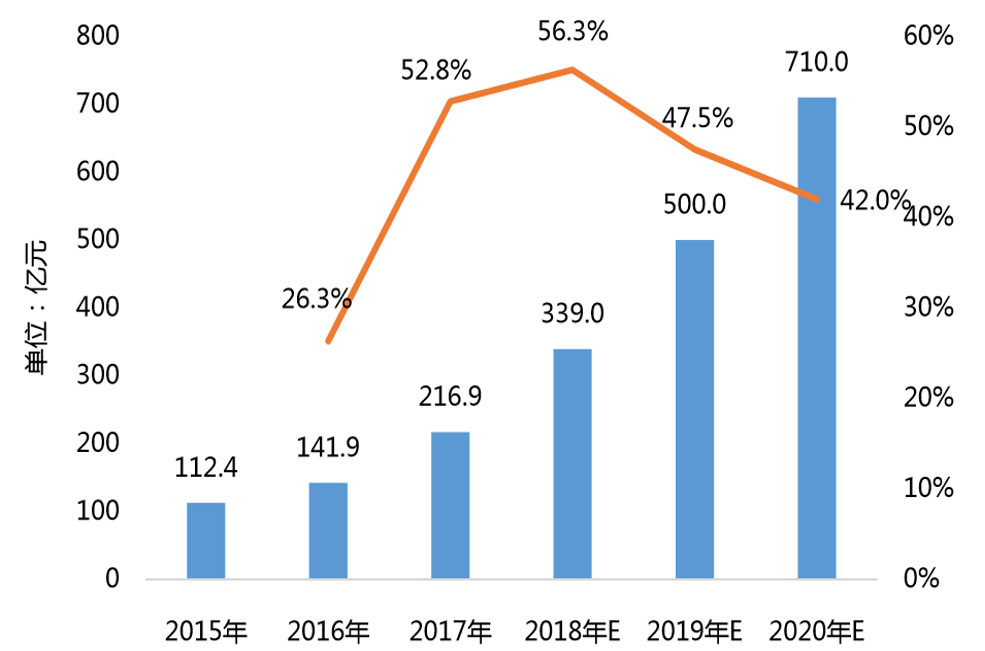
通过上图我们可以发现,近几年,国内AI行业高速发展,环比增速在45%左右,预计到2020年,整个国内的AI市场容量将达到710亿元,说完了整体市场容量,笔者再带大家看下当前人工智能市场的技术规模结构:
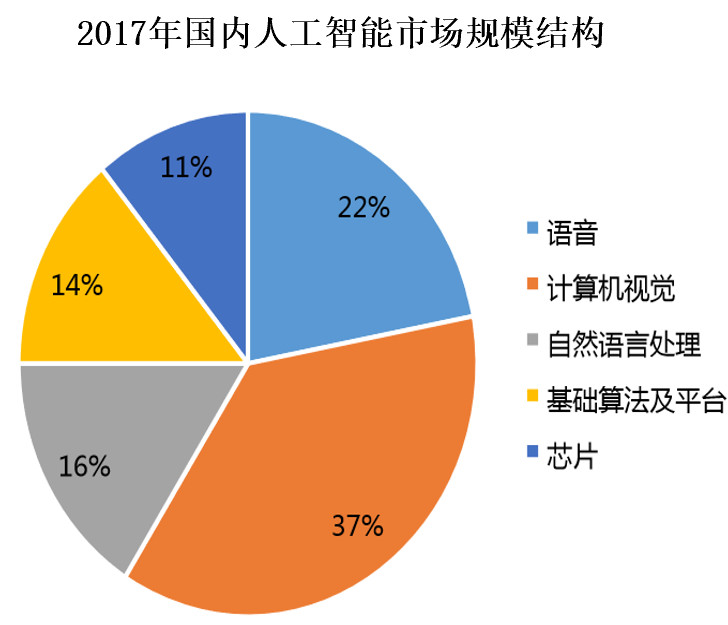
其中各个技术板块的主要技术应用分别如下:
- 语音:语音识别、语音合成、语音交互、语音评测、人机对话、声纹识别;
- 计算机视觉:生物识别(人脸识别、虹膜识别、指纹识别、静脉识别)、情感计算、情绪识别、表情识别、行为识别、手势识别、人体识别、视频内容识别、物体和场景识别、计算机视觉、机器视觉、移动视觉、OCR、手写识别、文字识别、图像处理、图像识别、模式识别、眼球追踪、人机交互、SLAM、移动视觉、空间识别、三维扫描、三维重建 ;
- 自然语言处理:自然语言交互、自然语言理解、语义理解、机器翻译、文本挖掘(语义分析、语义计算、分类、聚类)、信息提取、人机交互;
- ML/DL 算法及平台:机器学习、深度学习、算法平台 ;
- 基础硬件:芯片、高清图传设备、激光雷达、传感器、服务器。
从饼状图,可以看到,目前国内人工智能技术,主要在感知智能,感知智能正在突飞猛进,技术成熟度相对较高,而对于认知智能(自然语言理解等),仍然需要进一步的发展。
(2)应用层面, “AI+”和智能机器人占据主导
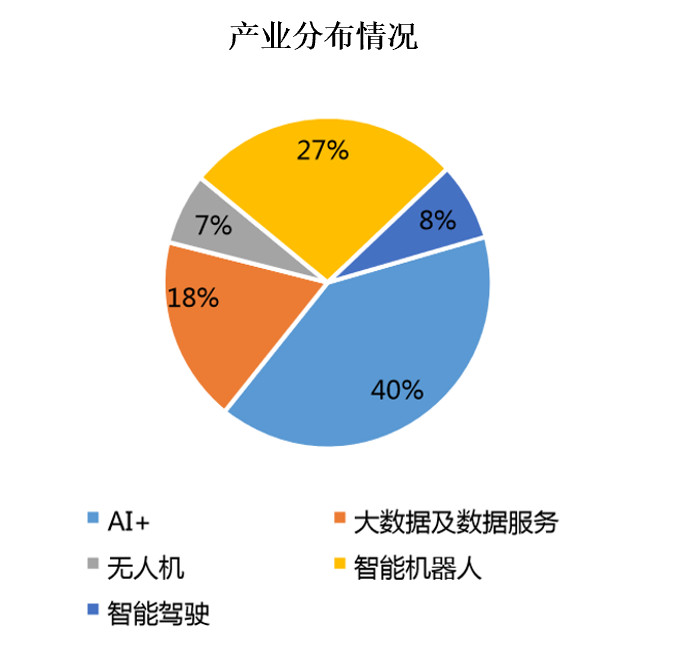
通过上图,我们可以发现现在在应用层面上,AI+的应用占比最大,达到40%,其次是智能机器人,达到27%,各个产业具体应用如下:
- 智能机器人(含解决方案):工业机器人(侧重生产过程,如搬运、焊接、装配、码垛、喷涂等)、行业服务机器人(应用于银行、餐厅、酒店、商场、展厅、医院、物流)、个人/家用机器人(虚拟助理、情感陪伴机器人、儿童机器人、教育机器人、家庭作业机器人(扫地、擦窗等)、家用安防机器人、车载机器人);
- 智能驾驶(含解决方案):智能驾驶、无人驾驶、自动驾驶、辅助驾驶、高级驾驶辅助系统(ADAS)、激光雷达、超声波雷达、毫米波雷达、GPS 定位、高精度地图、车载芯片、人车交互、车联网;
- 无人机(含解决方案):消费级无人机(娱乐、航拍) 工业无人机(农林、电力、物流、安防等领域);
- 大数据及数据服务:数据可视化、数据采集、数据清洗、数据挖掘、数据解决方案。
在AI+方面,当前AI和具体行业或场景的结合情况如下,其中最主要的场景分别为金融、制造、电商、医疗等。
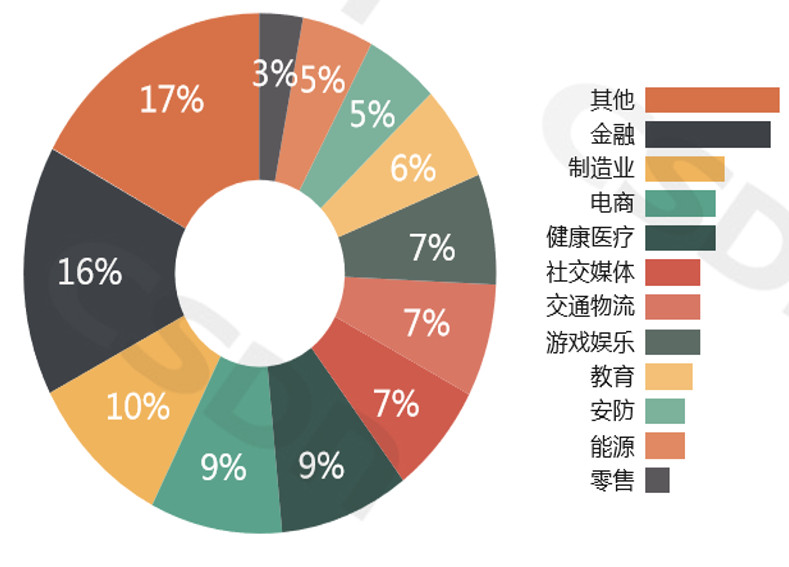
数据来源:2017 CSDN中国开发者大调查
(3)融资层面,融资金额逐年提高,单笔金额逐渐增大
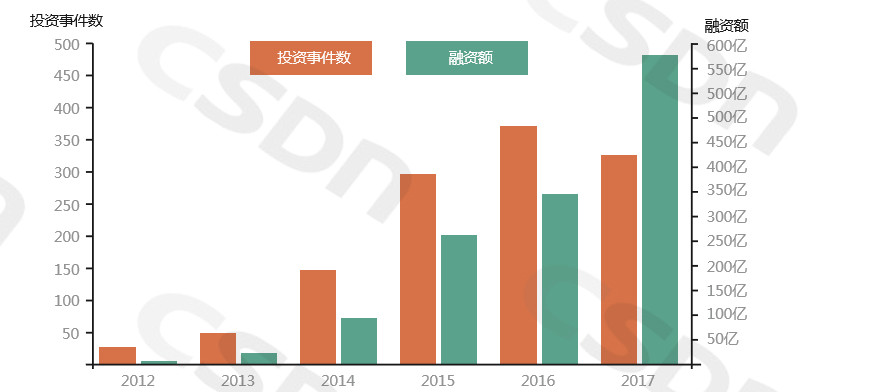
数据来源:IT桔子 2012-2017AI融资趋势
从2012年至今,我国AI领域共有1354家公司,投资事件1353起,投资总额为1448亿人民币。2012年,我国的AI投资事件共26起,投资金额为6亿元人民币,到了2017年,投资事件已经高达334起,投资总额已经超过550亿元人民币,相比2012年翻了上百倍。不过,相对2016年,2017年的投资事件有所下降,但是投资总额大幅上升,资本对于AI的热情还是值得肯定的。
三、人工智能发展背景
1. 人工智能发展史
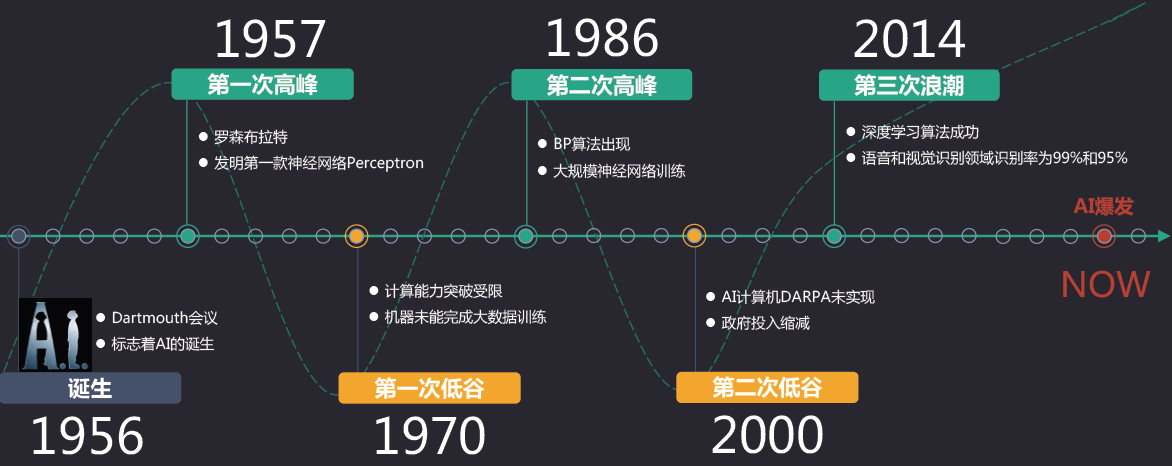
从1956年提出概念,到2016年大规模爆发,在这60多年里,人工智能一共经历了三起二落,在1970年和2000年,人工智能的发展陷入了低谷,原因主要是:
- 当时的算法和科技水平无法满足人工智能的需求,最后也都是依靠算法的进化和计算能力的提升而突破。
- 人工智能的应用达不到人们的预期,政府缩减投入。
当前,人工智能正处于第三次热潮。这次热潮除了结合技术以及算法的提高之外,最大特点是通过深度学习和大数据的结合,使得人工智能在多个领域找到了真实的应用场景,与具体业务场景相结合,开始在一些行业中发挥着巨大的作用。
2. 人工智能发展三要素
如果用一个公式来概括人工智能发展受那些因素影响,那么这个公式可以是AI=算力+算法+数据,关于这三者的关系,著名人工智能专家吴恩达曾有一个著名的比喻:发展人工智能就像用火箭发射卫星,需要强有力的引擎和足够的燃料,如果燃料不够,火箭无法将卫星推到合适的轨道;如果引擎推力不够,火箭甚至都不能起飞。而这当中,算法模型就好像引擎,高性能的计算机是打造引擎的工具,海量的数据就是引擎的燃料。
(1)算力,主要包含芯片+超级计算机+云计算

FLOPS是Floating-point Operations Per Second每秒所执行的浮点运算次数的英文缩写,它是一个衡量计算机计算能力的量,计算机每秒执行的浮点运算次数越多,算力越强,1GFLOPS (gigaFLOPS) =每秒10亿 (=10^9) 次的浮点运算。
注:浮点运算能力大小:
- 1MFLOPS (megaFLOPS) =每秒1百万 (=10^6) 次的浮点运算
- 1GFLOPS (gigaFLOPS) =每秒10亿 (=10^9) 次的浮点运算
- 1TFLOPS (teraFLOPS) =每秒1万亿 (=10^12) 次的浮点运算
- 1PFLOPS (petaFLOPS) =每秒1千万亿 (=10^15) 次的浮点运算
(2)算法
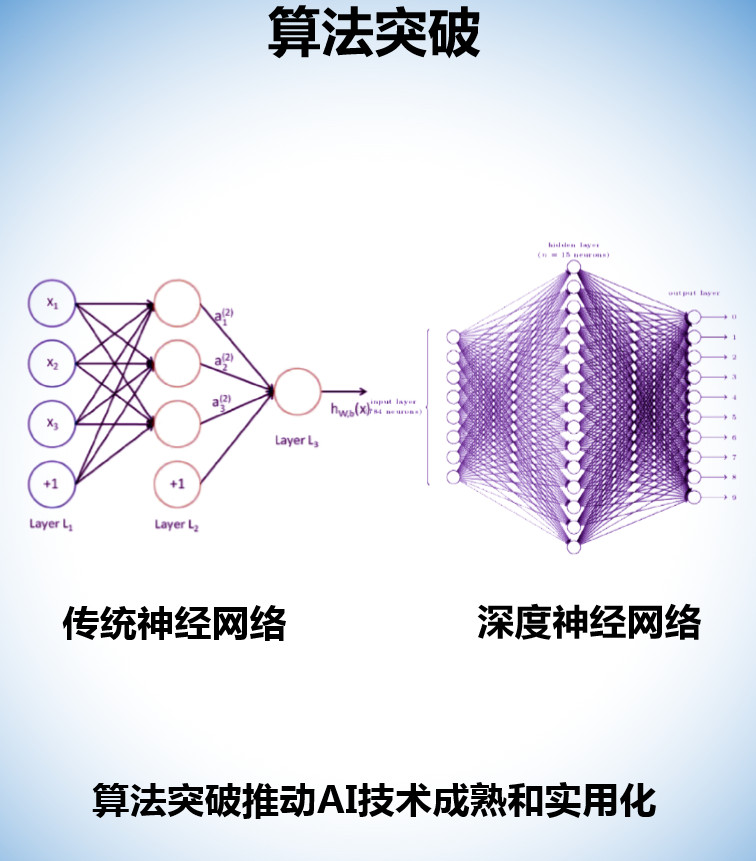
传统神经网络的时候,由于技术能力的限制,人工智能在很多行业都没法具体应用和落地,深度神经网络出现之后,人工智能的技术能力有了飞速的提升。
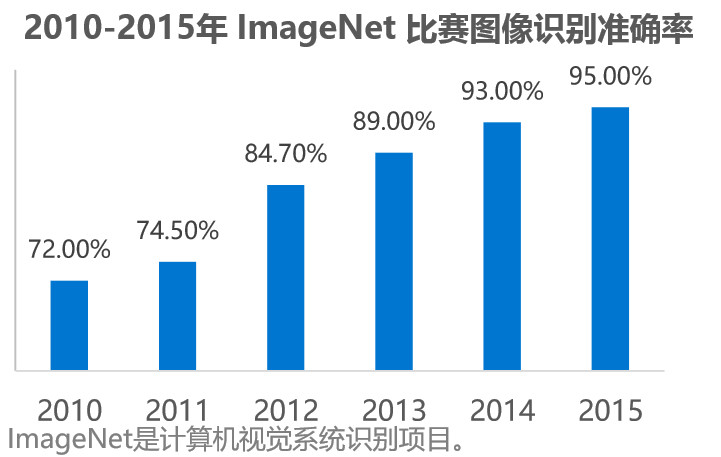
以计算机视觉为例:其主要识别方式发生重大转变,自学习状态成为视觉识别主流,机器从海量数据库里自行归纳物体特征,然后按照该特征规律识别物体。图像识别的精准度也得到极大的提升,从70%+提升到95%。
(3)数据
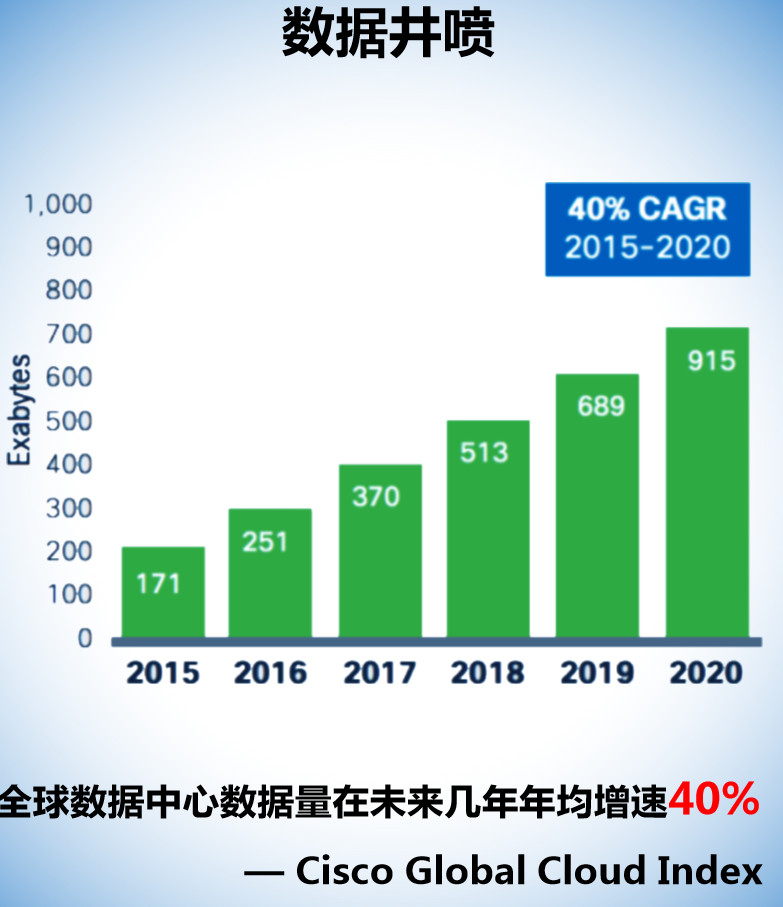
2017年全球人口有75亿,一个人,一年产生的数据量大约是52GB的信息, 虽然作为个体的我们的确非常的渺小,但是整个人工智能的发展也离不开我们每一个人的贡献,因为我们每个人无时无刻都在给AI输送着燃料。
四、人工智能的产业链分析
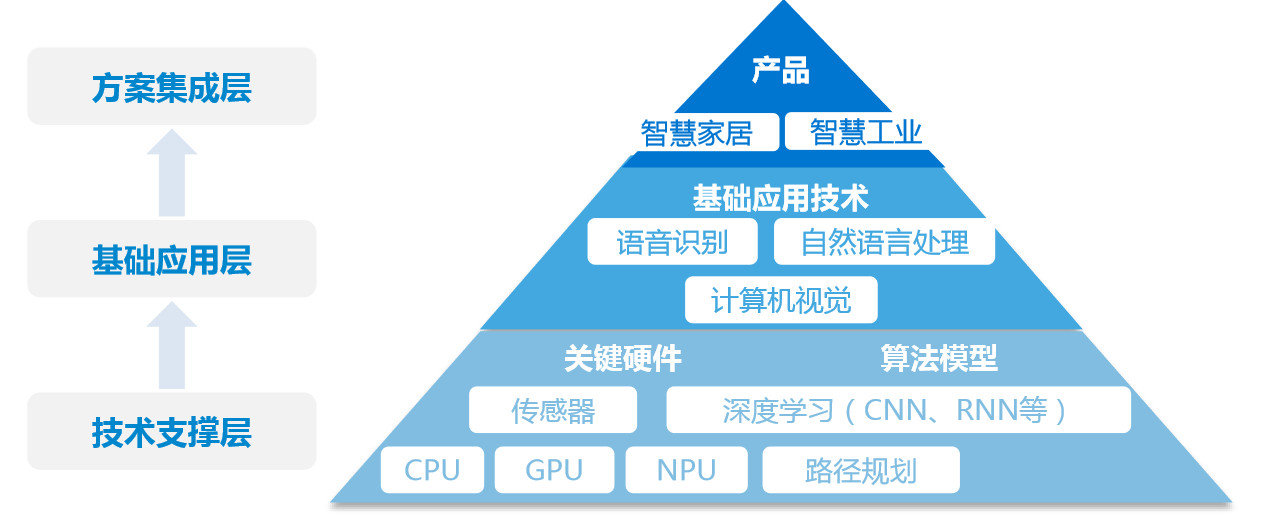
人工智能从底层到应用层,大致可以分为技术支撑层,基础应用层和方案集成层,下面笔者会对每块内容,做个说明。
1. 技术支撑层
(1)芯片
1)芯片分类
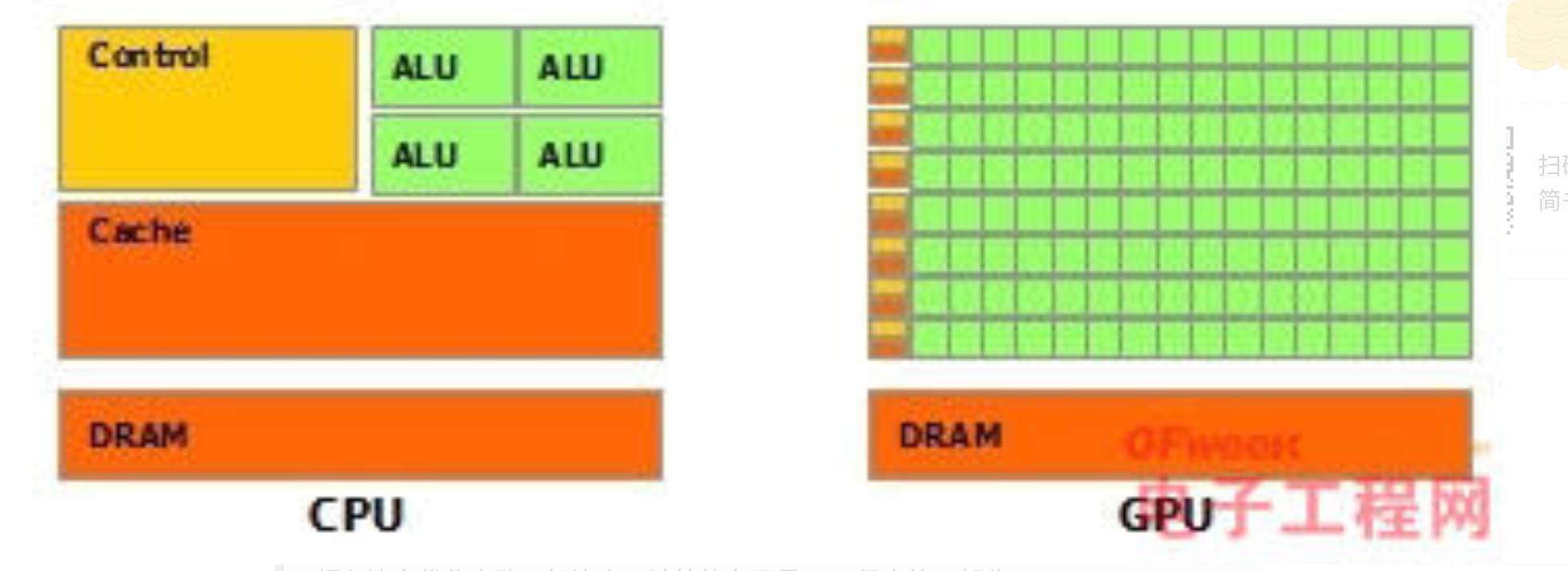
芯片一般是指集成电路的载体,由晶圆分割而成,芯片按照功能不同可分为很多种,有负责音频视频处理的,有负责图像处理的,还有负责复杂运算处理的,算法必须借助芯片才能够运行,不同场景及技术,对于芯片的性能要求也不一样。当前大家接触比较多的芯片应该就是CPU和GPU了。
CPU 基于高通用、强逻辑的设计—偏认知能力的应用
CPU需要很强的通用性来处理各种不同的数据类型,在大规模并行计算能力上极受限制,而更擅长于逻辑控制。核心:存储程序,顺序执行。
GPU是基于大吞吐量、高并发设计—偏感知能力的应用
和通用类型数据运算不同,GPU擅长的是大规模并发计算,这也正是密码破解等所需要的。
CPU和GPU的区别:
举个栗子:一个数学教授和100个小学生PK。
- 第一回合,四则运算,100道题。教授拿到卷子一道道算,一百个小学生各拿一道题各自算,教授刚开始算到第5题的时候,小学生集体交卷,第一回合小学生碾压教授。
- 第二回合,证明题。一道题,当教授搞定后,一百个小学生还不知道在干嘛…….
- 第二回合,教授碾压一百个小学生,这就是CPU和GPU的浅显比较。
高通用:除了四则运算、还可以有证明题、几何体、微积分题等等。
强逻辑:证明题,证明过程上下是有逻辑的,单独抽出来看一行是没有意义。
高并发:一下子100道题。
因为CPU的架构中需要大量的空间去放置存储单元和控制单元,相比之下计算单元只占据了很小的一部分,所以它在大规模并行计算能力上极受限制,而更擅长于逻辑控制。这方面,GPU刚好相反,但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
2)芯片上下游产业链情况
不同的芯片在不同的算法及应用场景下,功能和价值是不一样的,原因主要和集成电路设计的结构有关。

晶圆:芯片是半导体,主要材料是硅,制作硅的工艺,较小、较薄,节省材料,单位材料下可以做更多芯片。
专业封测:封装材料塑料、陶瓷、玻璃、金属等,完成封装后,便要进入测试的阶段,在这个阶段便要确认封装完的 IC 是否有正常的运作,正确无误之后便可出货给组装厂。
在芯片产业链上,越接近上游,附加值越高,技术门槛越大,资本投入的效益也越高。当前在芯片这块,Intel、IBM、三星这几家巨头企业在芯片上下游的工艺全有,整体产业链控制力强,而国内的中兴集团在通讯设备和手机这块,大量和核心元器件是从国外进行采购,一但发送贸易摩擦,很容易被国外掐断这块原材料的供应,比较容易受制于人。
3)未来, AI定制芯片必为趋势
任何一种产品或者商业模式在她刚出来的时候,当对于她在哪个行业具备较大经济价值的时候,通常都是先做通用化,然后再做垂直化,通过垂直化的服务优势,来提升整个产品以及商业模式的核心竞争力。按照上文所述,CPU和GPU都是较为通用的芯片,但是,随着行业的快速发展,人们对于芯片的个性化要求也越来越高,万能工具的效率永远比不上专用工具。
人工智能领域作为一个数据密集的领域,传统的数据处理技术难以满足高强度并行数据的处理需求。为解决此问题,继CPU和GPU之后,相继出现了NPU、FPGA、DSP等专门针对AI的芯片。
TPU—用于加速深度学习运算能力而研发的一款芯片
代表公司GOOGLE
原来很多的机器学习以及图像处理算法大部分都跑在GPU与FPGA(半定制化芯片)上面,但这两种芯片都还是一种通用性芯片。所以在效能与功耗上还是不能更紧密的适配机器学习算法,TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率提升。
NPU— 即神经网络处理器,利用电路模拟人类的神经元和突触结构
代表公司寒武纪
专门高效地进行 AI相关计算定制的处理器,就像GPU之于图形处理相关的计算,ISP之于成像相关的计算。NPU性能达到了1.92TFLOP,使用NPU计算比使用CPU计算要高出25倍的速度,50倍的能效比。
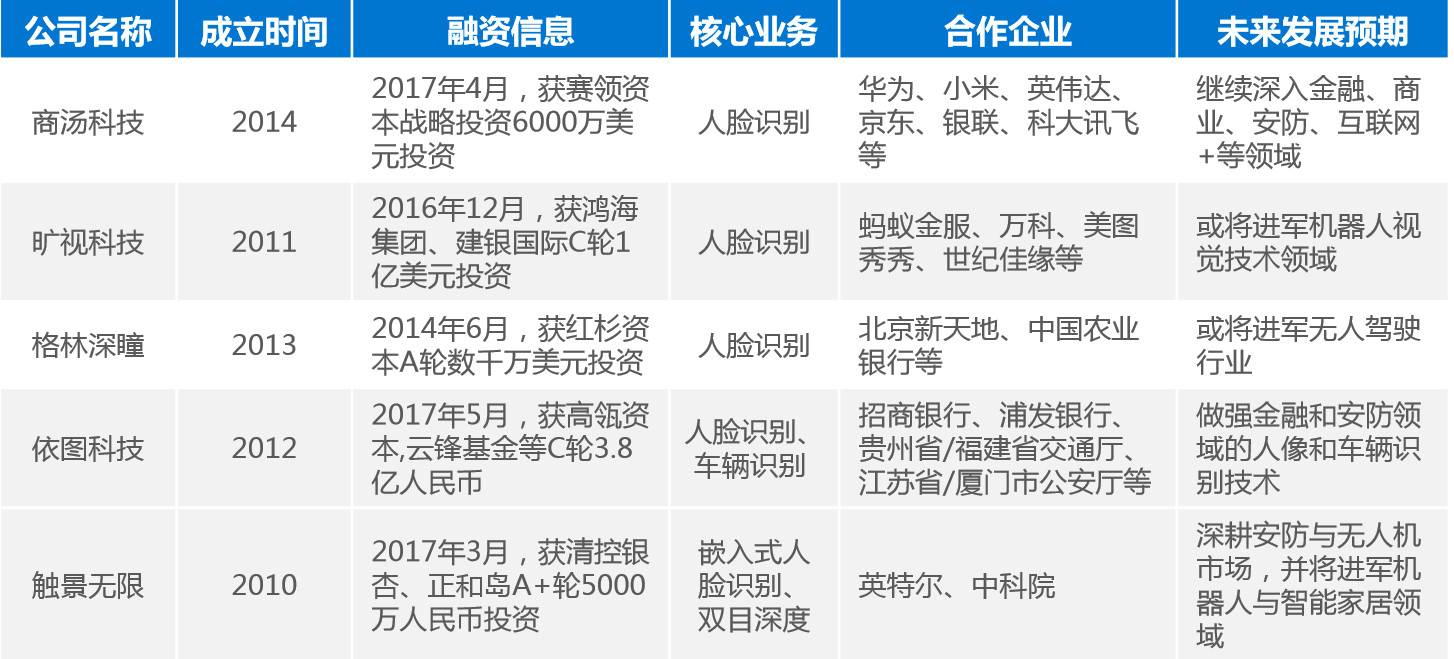
4)国内芯片企业介绍
(2)算法模型
笔者前面说了很多关于人工智能的介绍以及分析,那么到底怎么样才是智能,也就是人工智能的核心是什么,在笔者看来无非四个字——机器学习。
机器学习是需要算法来支持的,算法的作用:对数据进行归纳和演绎,最终目的是提高识别效率和准确率 ,然后对真实世界中的事件做出决策和预测。人工智能的核心就是通过不断地机器学习,而让自己变得更加智能。

那什么又是机器学习呢?
机器学习是让计算机有能力在不需要明确编程的情况下,用大量的数据来“训练”,从数据中学习如何完成任务。在深度学习出现之前,机器学习领域的主流是各种浅层学习算法, 如神经网络的反响传播算法(BP算法)、支撑向量机(SVM)、 Boosting、Logistic Regression等。这些算法的局限性在于对有限样本和计算单元的情况下对复杂函数的表示能力有限,对复杂数据的处理受到制约。
1)深度学习是通过模拟大脑结构的多层神经网络进行学习
大脑中的神经元,又称神经细胞,是构成神经系统结构和功能的基本单位,它由细胞体和细胞突起构成,每个神经元有好几个数突,只有一个轴突,可以把兴奋从胞体传送到另一个神经元或其他组织,如肌肉或腺体。
但与大脑中一个神经元可以连接一定距离内的任意神经元不同,人工神经网络具有离散的层,每一次只连接符合数据传播方向的其它层。
深度学习的“深度”指的就是多层神经网络的层数较多,模型结构的深度,通常有5层、6层,甚至10多层的隐层节点,每层相当于一个可以解决问题不同方面的机器学习。利用这种深层非线性的网络结构,深度学习可以实现复杂函数的逼近,将表征输入数据分布式表示,继而展现强大的从少数样本集中学习数据集本质特征的能力,并使概率向量更加收敛。
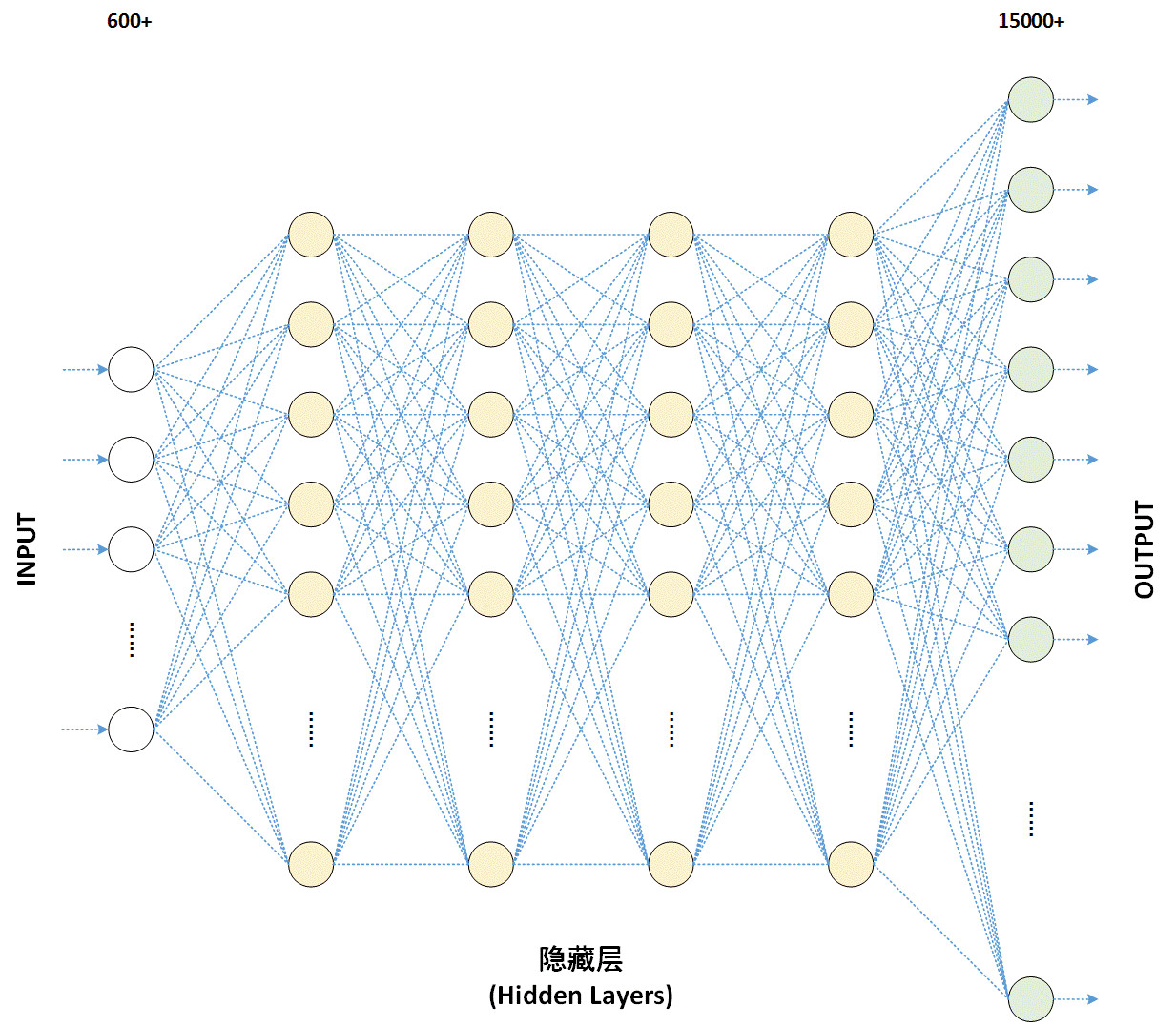
2)深度学习的出现,使得人工智能在很多行业具备了价值实现的可能性
深度学习出现之后,计算机视觉的主要识别方式发生重大转变,自学习状态成为视觉识别主流。即,机器从海量数据库里自行归纳物体特征,然后按照该特征规律识别物体。图像识别的精准度也得到极大的提升,从70%+提升到95%,在医学影像领域,95%的精度识别已经具备一定使用价值,而精度识别达到达到97%以上后,将具备辅助诊断价值。
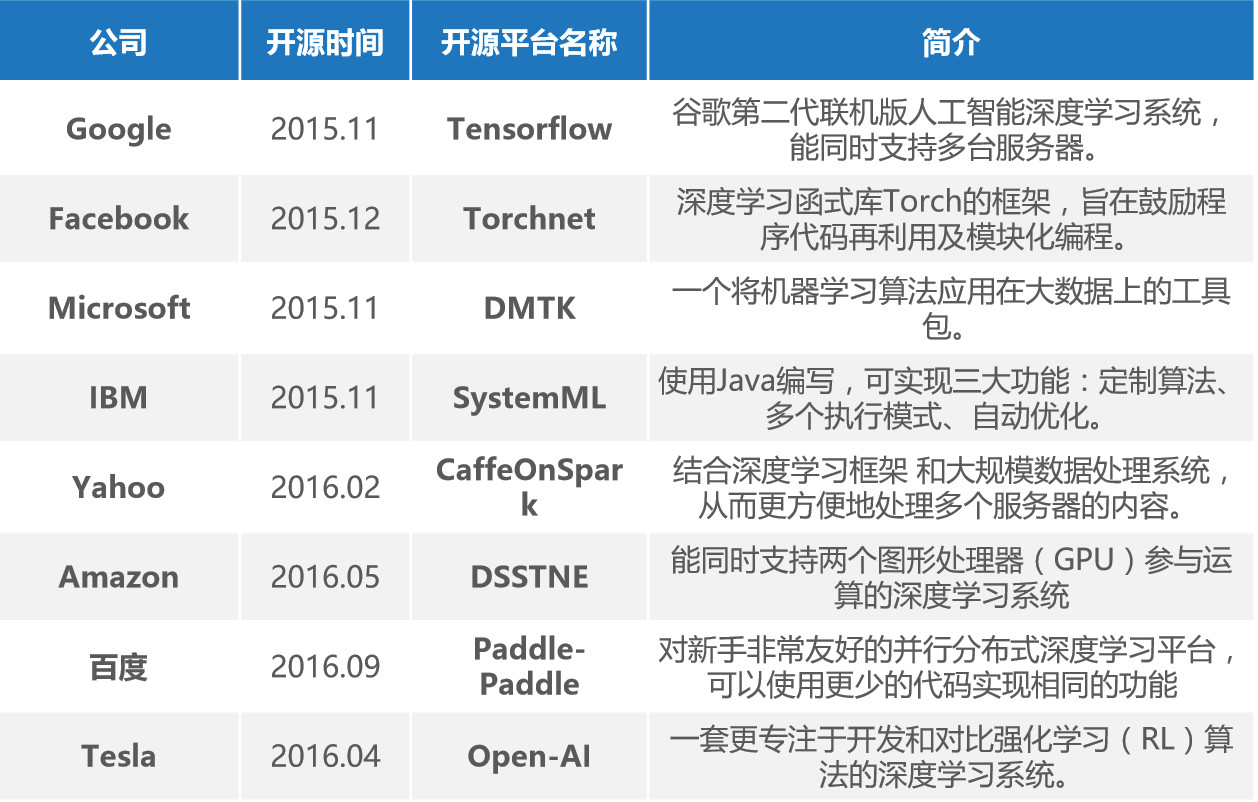
3)目前深度学习框架的开源已经成为了趋势
机器学习和深度学习是需要靠算法支撑的,算法是需要不断的利用数据进行训练和优化。自从深度学习取得突破性进展以后,巨头们频频开源,当AI公司们使用开源平台进行算法的迭代时,开源平台可以获取数据,以及市场对应用场景热度的反馈,加速模型的训练。
在这样的背景下谷歌公司于2015年2月15日开放了TensorFlow1.0版本。在深度学习加速发展的今天,代码和数据库都在迅速的更新中,开源所构建的开发者生态是极为重要的。
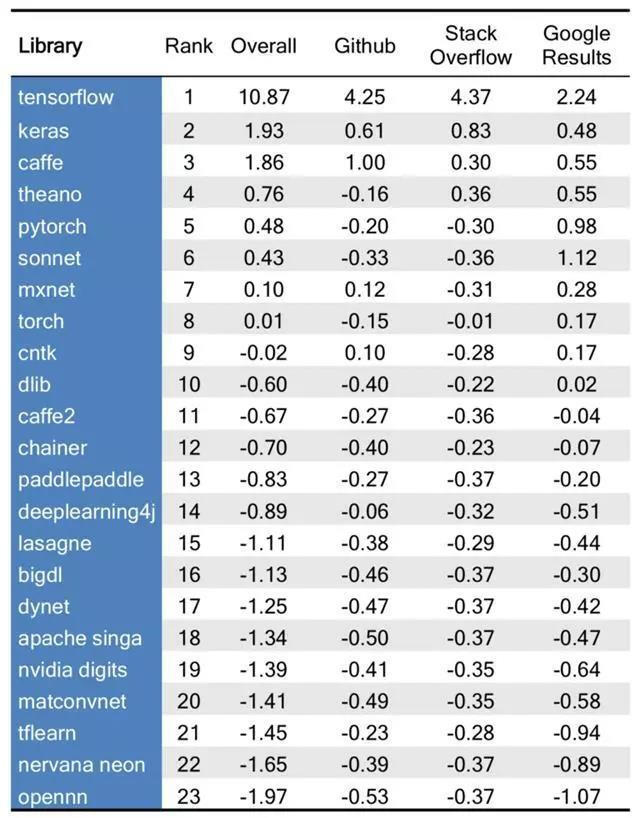
4)算法和基础应用技术的关联

上图是笔者根据自身投资行业经验以及理解,做得一个人工智能算法对于基础应用技术的一个难易程度关联,场景化程度越高,对于算法难度的要求也会也会越大。
2. 基础应用层

(1)语音识别
技术原理:
所谓语音识别,是将声音信号转化成数字信号,然后通过特征提取,进行归纳演义,推测出对应的文字,语音识别的主要难度主要在两个方面
首先是数据的获取、清洗。语音识别需要大量细分领域的标准化语料数据作为支撑,尤其是各地方言的多样性更是加大了语料搜集的工作量。
第二个难点是语音特征的提取,目前主要通过具备多层神经网络的深度学习来解决,多层的神经网络相当于一个特征提取器,可对信号进行逐层深化的 特征描述,最终从部分到整体,从笼统到具象,做到最大程度地还原信号原始特征。
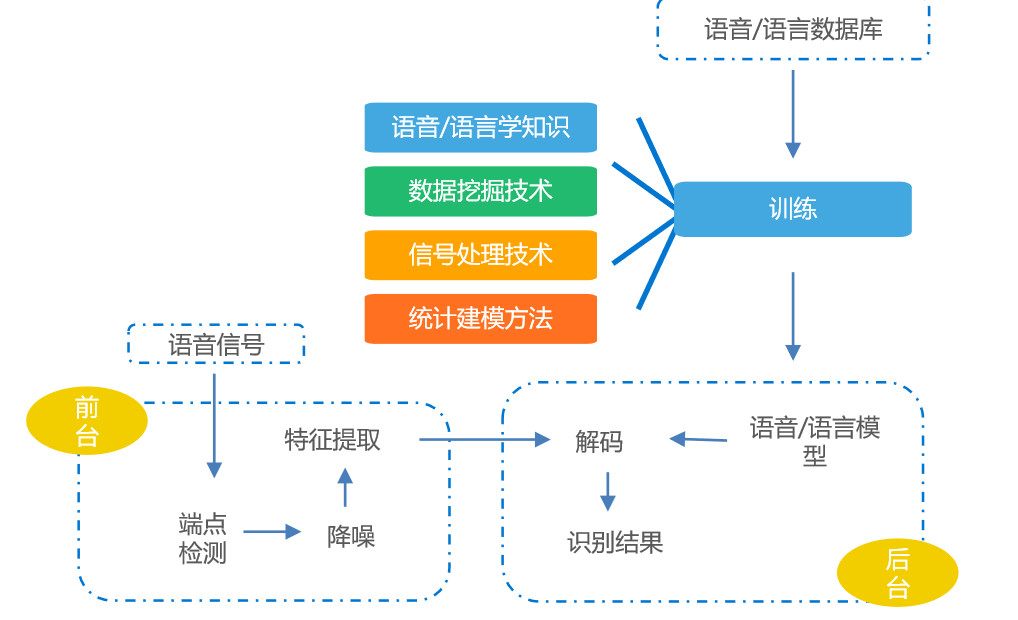
应用场景:

投资价值及机会:
语音识别虽市场庞大但已出现寡头,留给创业公司的机会不多,据Research and Markets研究报告显示,全球智能语音市场将持续显著增长,预计到2020年,全球语音市场规模预计将达191.7亿美元。根据Capvision报告显示,从语音行业市场份额角度来看,全球范围内,由Nuance领跑,国内则是科大讯飞占据主导地位。
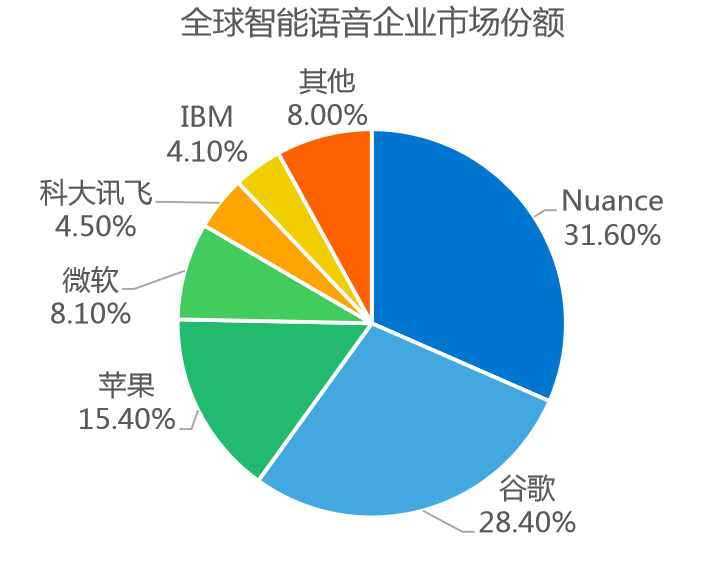
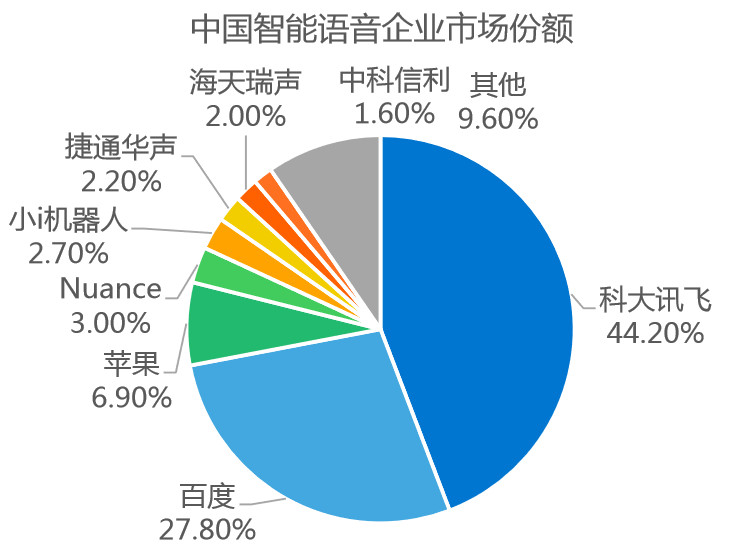
以科大讯飞为例,截止2018年
1)开放平台
讯飞开放平台开发者达51.8万(同比增长102%),年增长量超过前五年总和;应用总数达40万(同比增长88%),年增长量超过前五年总和;平台连接终端设备总数累计达17.6亿(同比增长93%)。科大讯飞当前将语音识别很多功能模块SDK化,根据开发者终端APP或者是设备每月的数据并发数来进行收费。
2)语音识别准确率
当前语音识别准确率达到98%以上,基本能够满足大量的的业务场景和需求。
3)智能教育、政法、城市服务程度很深
初创公司想在这三个行业和科大讯飞竞争很难。
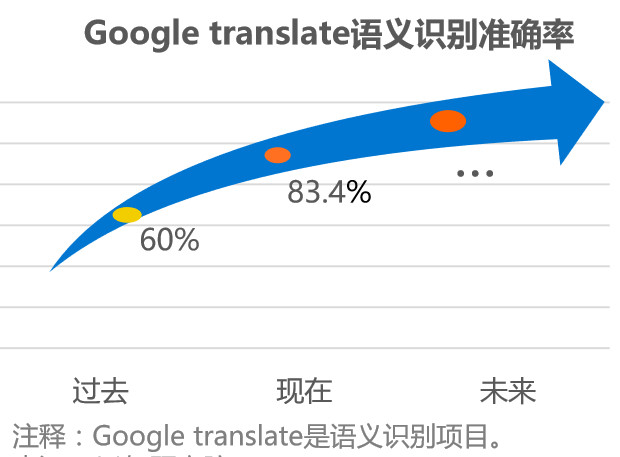
(2)语义识别
技术原理:
语音识别解决的是计算机“听得见”的问题,而语义识别解决的是 “听得懂”的问题。自然语言处理(NLP)通过建立计算机框架来实现该语言模型,并根据该语言模型来设计各种实用系统,根据统计学原理推算出用户想表达的意思,对用户行为进行预测,然后给出对应的指令或者是反馈。
当前,NLP技术瓶颈主要还是在语义的复杂性,包含因果关系和逻辑推理的上下文等,现在解决这些问题的思路主要还是依赖于深度学习。
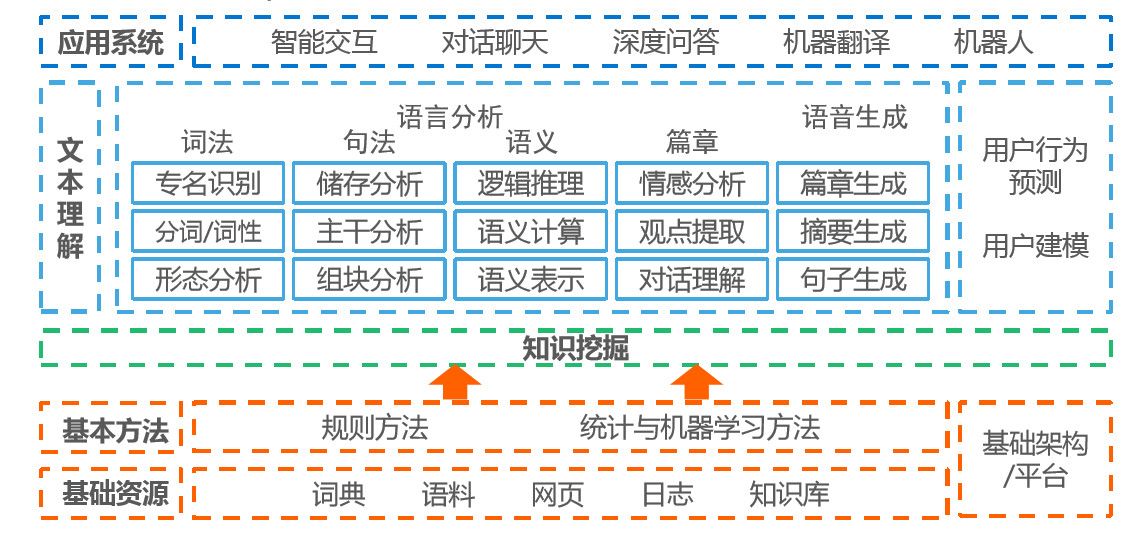
应用场景:
投资价值及机会:
当前语义识别领域,大的科技巨头乐衷于收购,小而美的企业更偏好细分场景。

关于语义识别领域的创业公司,国内代表企业有出门智能360、出门问问、三角兽、蓦然认知等。
大公司更侧向于做平台方面的通用技术,基于平台,如果有好的项目出现,直接收购。做小而美的公司,在特定场景下的语义分析,难度要比通用行业的语义分析难度低,准确率甚至可以达到85%以上,原因是基于特定场景下的语料分析,由于语料相对特定,可以在一定程度上提高准确率。
智能客服:智齿科技 小I
法律咨询:无讼、法律谷等
(3)计算机视觉
技术原理:
计算机视觉在技术流程上,首先要得到实时数据, 此步骤可通过一系列传感器获取,少部分数据可直接在具备MEMS功能的传感器端完成处理,大部分数据会继续传输至大脑平台,大脑由运算单元和算法构成,在此处进行运算并给出决策支持。
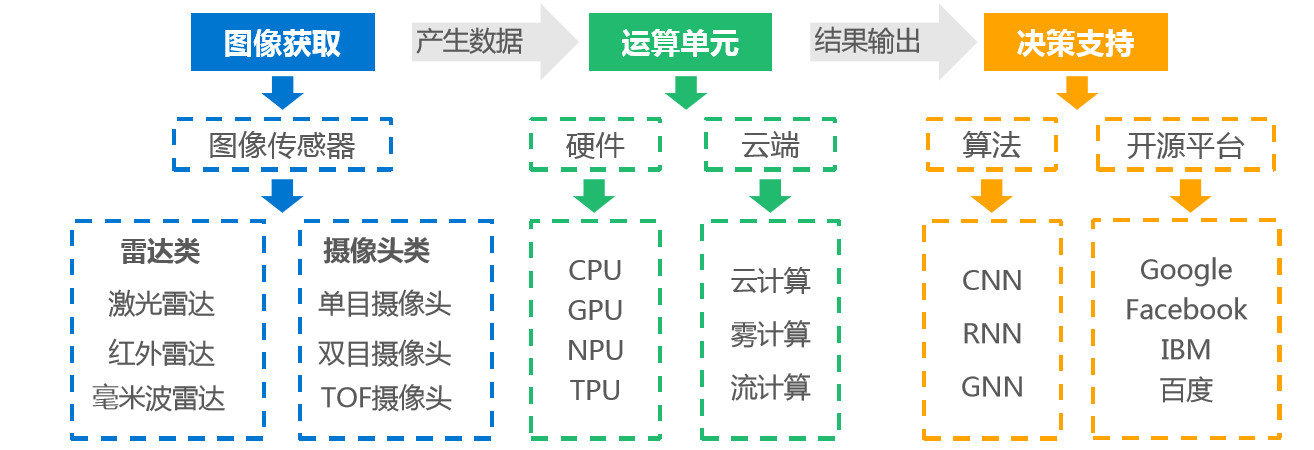
应用场景:
计算机视觉应用场景可分为两大类:图像识别和人脸识别,每类又可继续划分为动、静共四个类别, 基本覆盖了目前计算机视觉的各项应用场景。其中动态人脸识别技术是目前创业热度最高的细分领域,尤其是金融和安防场景,是其重点布局场景。
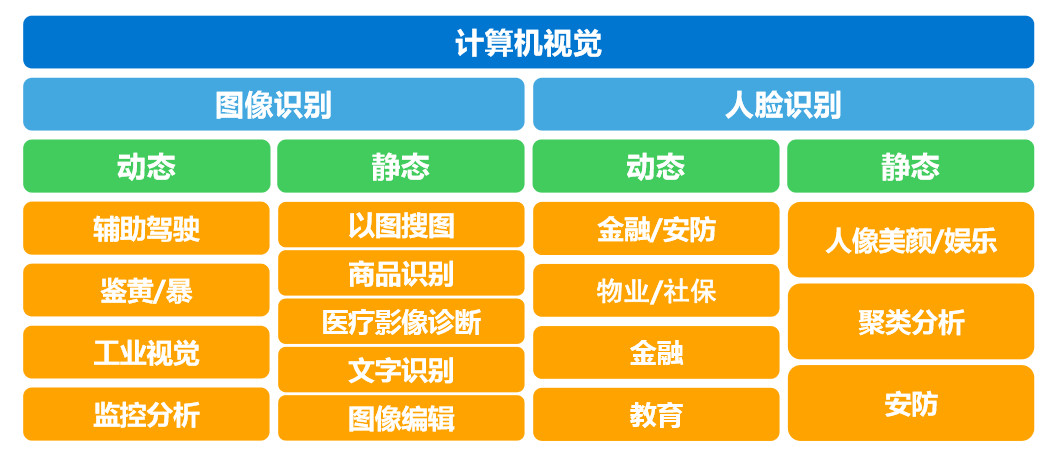
投资价值及机会:
对于计算机视觉而言,其主要瓶颈在于受图片质量、光照环境的影响,现有图像识别技术较难解决图像残缺、光线过爆、过暗的图像。此外,受制于被标记数据的体量和数量,若无大量、优质的细分应用场景数据,该特定应用场景的算法迭代很难实现突破。当前,计算机视觉市场技术较为成熟,第一梯队格局已经形成,留给创业公司的机会已经不大。
五、总结
这篇文章是笔者就最近看的一些人工智能项目,结合自己的投资经验,做得一个行业梳理,概括来说:
1)目前AI的发展仍处于早期,感知技术取得一定成就,认知技术发展仍待突破;
2)芯片的未来,AI定制芯片必为趋势,创业公司在垂直领域AI芯片的研发领域仍有机会;
3)算法是竞争的一个障碍,但AI如何结合生活和业务场景,进行落地,才是真正的难点;
4)语义识别发展瓶颈仍然较大,小而美的企业具备收购价值;
5)有一手数据源、能够与实际业务相结合的公司有望建立起自身的竞争壁垒,数据将成为制约AI公司在行业领域发展速度以及竞争门槛的重要要素。
当前人工智能行业仍然处于一个投资风口期,希望通过这篇文章,能够给有志于在这个行业中创业或者是进行产品设计的人一定的启发。
作者:阿旺,著名投资人兼连续创业者,会从自身投资以及创业经历,不定期输出各类行业研究,如您想了解更多关于创业以及投资方面的内容,欢迎关注本人公众号号:awangblog
本文由 @阿旺 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: