干货分享 | 数据统计埋点工作框架及细节规范
作为数据产品经理,对统计埋点一定不陌生,每个版本多少都会涉及到部分统计需求。如何做好产品上线前数据指标的统计埋点,以及产品上线后的版本分析报告?本文笔者将会给结合自身工作经验,给大家总结一些具体思路和方法。

明确定位与工作重心
数据产品经理是让数据产生价值(决策、增长、收入)的设计者、实现者和推行者。如何理解这样的定位呢?
首先,最基础的是要熟悉数据工具平台与产品业务,其次,要学会逐步建立产品完整的数据指标体系,最后,是能够通过数据分析解读驱动业务发展。
具体拆解来看,主要包含:
(1)数据层面
- 源数据层:数据源的采集、埋点(客户端访问日志、服务端业务数据库表、sdk等)
- 数据加工层:结合业务,对收集到的数据进行加工、清洗(join)等操作
- 数据仓库层:依赖结构化规范的数据表,建设和维护数据仓库
- 数据应用层:规划与设计数据指标体系(构建核心指标框架;产品、运营等指标建设)
- 数据访问层:结合平台及应用产品,支撑业务方数据需求(如:统计平台、数据可视化平台、资源调度平台、渠道后台、用户画像平台、abtest平台等)
(2)产品层面
- 明确产品形态及定位,熟知业务功能(数据异动跟踪分析、数据解读与答疑)
- 数据驱动产品发展规划(版本迭代、数据反馈推进)。
根据基础数据体系,数据产品的工作基本上需要涵盖从数据源到最终数据应用、访问层的各个环节。做好产品上线前数据指标的统计埋点工作,以及产品上线后的版本分析,侧重点主要在于:数据应用层面(规划和设计项目核心指标,满足各业务方的数据需求);数据访问层面(做好数据分析与解读,对上线数据进行监测以及效果分析)对数据源的处理、数据加工及数据仓库,本文暂不展开说明。
熟悉业务逻辑与流程
1. 工作流程
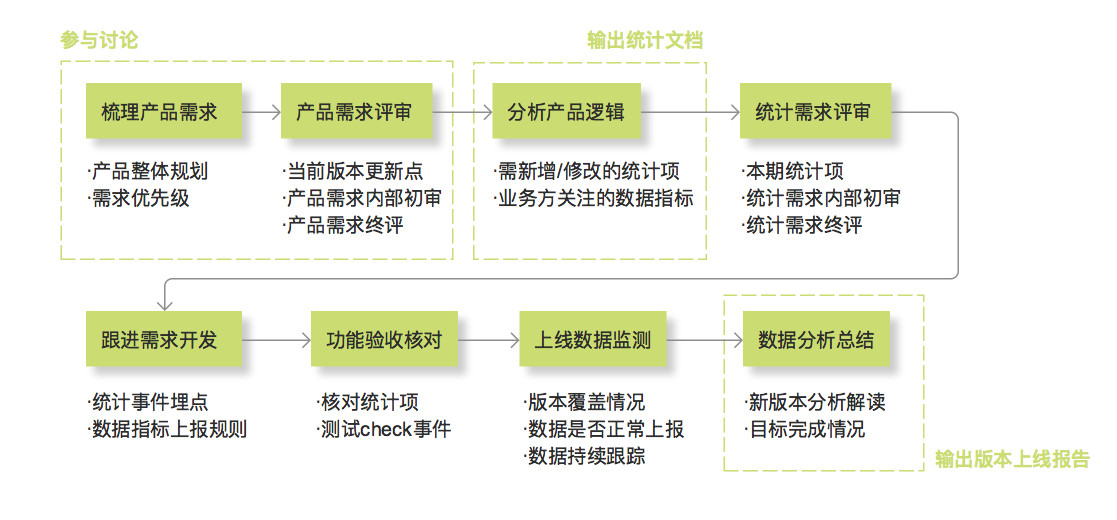
数据统计埋点工作流程说明
step1:梳理产品需求
作为数据产品经理,在版本迭代阶段,主要是 从数据的角度出发去思考业务需求和问题点 。
在产品需求文档的梳理过程中,可以就之前版本发现的问题参与需求的收集与讨论。通过数据论证,提出相关的优化改进方案或建议,给出更加合理的产品规划和需求优先级。
step2:产品需求评审
产品需求文档一般包含:
- 文档说明(功能优先级、修改历史)
- 需求分析(需求背景、需求价值或、预期目标、数据参考)
- 结构流程(业务流程和产品框架)
- 原型交互(客户端逻辑、服务端逻辑)
- 数据埋点
业务产品经理主导当前版本的功能规划及需求输出。数据产品经理则主要是负责数据埋点部分,需要我们全程参与需求文档的评审, 理解产品功能结构和开发实现逻辑 。
ps:由于各公司逐步重视 “通过数据驱动业务决策”。数据相关工作,部分公司会将其单独拆解出来,作为数据产品经理或数据分析师的主要职责。
step3:分析产品逻辑
当产品需求文档完成最终评审,意味着当前版本需求不会再做大的改动。此时就需要开始分析产品逻辑,理解产品核心目标和当下主要的问题点。
除了需要弄明白产品承载了哪些重要的信息和功能,以及这些信息和功能的想要达到的需求目标。还要通过深入的分析, 挖掘各业务方重点关注的数据指标是什么,确立产品的第一关键指标。 (即分析是在什么样的场景下要解决什么业务问题,为了解决这个业务问题,要通过什么样的数据指标衡量),项目中不同的角色关注的问题不同,我们可以更好地给出他们最想看的数据。
- 产品(功能点击量、使用率、功能留存、核心路径转化、改版效果、用户行为等)
- 运营(用户新增、活跃、流失、付费转化、分享等)
- 渠道(渠道新增、落地页pv/uv、渠道转化、渠道留存率、ROI等)
step4:统计需求评审
统计需评阶段,主要是 进行统计事件的设计和给出数据采集埋点方案 。一般情况下,在做统计需求评审时,可以优先梳理产品功能结构图,将产品的功能模块及跳转流程梳理出来,想清楚上游入口和下游出口是什么。这样做的目的也是在进行更加合理的数据指标体系的设计,以及避免埋点的重复。
ps:由于项目迭代节奏较快,推行敏捷开发(“小步快跑模式”),有时统计需求评审会和产品需求评审同时进行,就需要和业务产品保持紧密的信息对接。
step5:跟进需求开发
当产品和统计需求评审完成后,接下来会进入需求研发阶段。在开发实现产品功能需求时需要我们高频沟通,这样做的目的是为了保证数据采集的质量及数据分析的准确性。
step6:功能验收核对
除了产品功能的核对,数据层面主要核对内容是:
- 数据上报节点或时机是否准确
- 数据采集的结果是否真实有效/重复上报
- 新增/修改的统计项是否会影响到其他功能的上报规则
step7:上线数据监测
发版后,随着版本覆盖率的提升数据会逐渐起势。一般情况下,需要密切监测上线前3d的数据情况,并在3d后给出一份初步的数据波动趋势分析文档,主要目的是:发现是否存在统计上报异常的数据指标,产品功能若出现较大问题,也要及时关注可能会影响到的统计点。根据问题紧急程度,采取发紧急修复包或其他方式解决。
step8:数据分析总结
上线后若不存在什么问题。即可输出当前新版本的数据分析报告,主要用于向项目组成员同步该版本的数据分析结论和迭代优化建议,建议在发版2周后再拉取数据指标进行分析总结。因为时间越短,覆盖率越低,数据量级小,就不太能够说明问题。
2. 细节规范
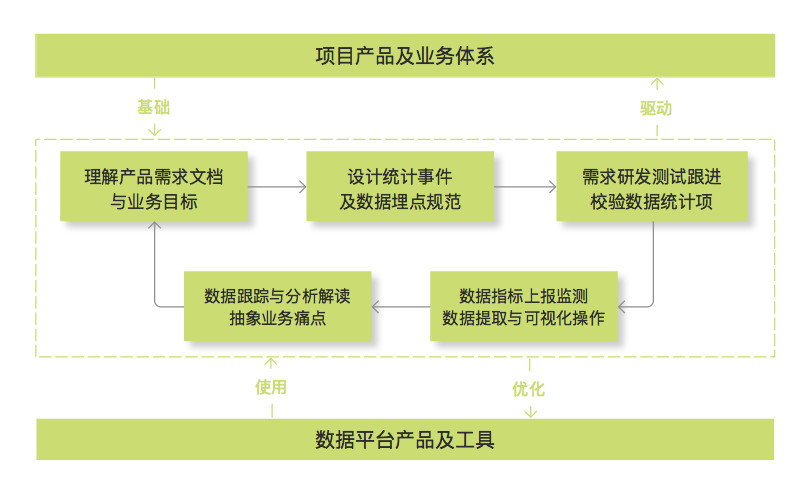
# 上线前:数据统计埋点
(1)理解产品需求文档与业务目标
在上线前做好数据统计埋点工作,最重要的就是需要理解项目产品和业务体系。梳理产品需求、参与产品需求评审、分析产品逻辑的工作必不可少。
如何更好地理解呢?
除了深入沟通理解产品需求文档(prd),我们自己可以去整理当前产品功能结构图、核心业务流程图或用户使用路径图。

如图为美图秀秀v6.9.6版本- 美化功能用户使用路径图(参考)。通过梳理,主要目的是对产品的功能结构、核心业务流程及信息框架有清晰的认知,帮助我们更好的进行数据相关工作。
(2)设计统计事件及数据埋点规范
做好了准备工作,接下来最主要的就是进行统计事件的设计和给出数据采集埋点方案。本文暂不讨论接入第三方统计sdk的方式进行埋点的相关内容。统计事件的设计,就是做到针对某个具体页面,定义当前页面中用户的点击或其他触发行为并准确上报,从而提取数据进行分析,主要从用户行为角度出发。
比如页面中出现的某个按钮,想知道用户是否点击该按钮或点击的频次,统计事件就要记录用户点击该按钮的行为数据(消息数/设备数)。
如何通过用户行为找到统计事件的对应关系?
- 用户行为:分析用户行为,找到该行为相关的信息;
- 事件定义:根据相关信息,定义该行为对应的事件及参数。
说明一下,在版本迭代的过程中,新版本的事件无需全部重新埋点。
历史已有的统计事件只要有涉及到的,可列入测试check事件, 版本新增的统计事件列入本期统计项。 最终可汇总一份整体的数据统计事件库,每次只需在历史已有的内容里新增或修改补充当前新版本的统计项,也方便我们进行长期迭代与维护。通过用户行为找到统计事件的对应关系后,即可整理出我们最重要的统计埋点文档。
统计埋点文档主要包含:
- 更新说明(文档更新时间、更新内容记录)
- 本期统计项(新增/修改的统计事件list)
- 本期check事件(新增/修改的统计事件check+可能影响到的统计事件check)
- 后台全部展示事件(整体的数据统计事件库)
举个例子
产品功能:美化图片主功能中,新增马赛克
用户行为:用户在美图秀秀首页点击“美化图片”按钮-点击“马赛克”功能-选择素材使用-保存
用户行为与统计事件的对应关系(参考):
统计文档,本期统计项sheet表(参考):


(3)需求研发测试跟进及校验数据统计项
根据我们输出的统计文档,统计文档中“统计规则”的描述,就要求清晰定义该统计事件采集的节点和上报逻辑,需要及时和开发跟进沟通;而统计文档中“本期统计check事件”则需要详细和测试进行核对。通常,公司优秀的开发和测试也可以更好的协助我们,对事件统计的规则做优化调整,提高数据存储及读取的效率。
# 上线后:版本分析思路
(4)数据指标上报监测及数据提取、可视化操作
学会使用公司提供的数据平台产品及工具,帮助业务或数据负责人更快速高效的获取数据。在我们进行版本迭代的过程中,数据指标体系的日益完善会帮助我们更好的开展数据分析。
数据后台支持产品新增活跃留存、自定义事件等数据指标的快速提取,也可以自主配置。同时,平台上直观、友好的项目数据可视化设计也能提升我们的分析效率,更快驱动业务发展。
(5)数据跟踪与分析解读、抽象业务痛点
数据分析的最终价值体现在能够通过数据发现问题,抽象出业务痛点和需求。并不是项目中的每个人都能给出专业全面的分析及结论。数据产品则需要长期跟踪产品核心数据指标以及产品迭代功能数据指标,产出版本迭代数据报告、以及其他阶段性的数据报告。
版本分析报告的主要思路是:
- 基础指标上线前后变化趋势(大盘新增活跃留存波动)
- 功能指标上线前后变化趋势
- 版本主要更新点数据
- 主要数据结论及优化建议
写在最后
数据统计埋点工作的基础还是在于对业务的深度理解。我们要做的不仅是完成一个数据指标的上报,更重要的是通过不同纬度的数据指标,更加全面具体的去分析业务情况。
本文阐述的内容仅作为个人工作的总结和沉淀,如有疑问,欢迎与我讨论交流。感谢阅读~
本文由 @Sherily◡̈ 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: