超全面的语音交互知识总结:从原理、场景到趋势
2019年全球语音交互市场规模达到13亿美元,预计2025年全球语音交互市场规模将69亿美元,目前以广泛应用到智能家居、车载语音、智能客服等行业和场景。笔者从事语音交互产品一年有余,针对语音交互的概念定义、优劣势、适用场景和产品、未来发展等进行梳理总结。

1. 什么是语音交互?
语音交互(VUI)指的是人类与设备通过自然语音进行信息的传递。一次完整的语音交互需要经历ASR→NLP→Skill→TTS的流程:

(1)ASR
用于将声学语音进行分析,并得到对应的文字或拼音信息。语音识别系统一般分训练和解码两阶段:
- 训练即通过大量标注的语音数据训练数学模型,通过大量标注的文本数据训练语言模型;
- 解码,即通过声学和语言模型将语音数据识别成文字。
声学模型可以理解为是对发生的建模,它能够把语音输入转换成声学表示的输入,更准确的说是给出语音属于某个声学符号的概率。语言模型的作用可以简单理解为消解多音字问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。
(2)NLP
用于将用户的指令转换为结构化的、机器可以理解的语言。NLP的工作逻辑是:将用户的指令进行Domain(领域)→Intent(意图)→Slot(词槽)三级拆分。
以“帮我设置一个明天早上8点的闹钟”为例:该指令命中的领域是“闹钟”,意图是“新建闹钟”,词槽是“明天8点”。这样,就将用户的意图拆分成机器可以处理的语言。
(3)Skill
也即AI时代的APP。Skill的作用就是:处理NLP界定的用户意图,做出符合用户预期的反馈。
(4)TTS
即语音合成,从文本转换成语音,让机器说话。TTS业内普遍使用两种做法:一种是拼接法,一种是参数法。
- 拼接法即从事先录制的大量语音中,选择所需的基本发音单位拼接而成。优点是语音的自然度很好,缺点是成本太高,费用成本要上百万。参
- 数法指使用统计模型来产生语音参数并转化成波形。优点是成本低,一般价格在20万~60万不等,缺点是发音的自然度没有拼接法好。但是随着模型的不断优化,现在参数法的效果已经非常好了,因此业内使用参数法的越来越多。

2. 语音交互有哪些优劣势?
PART 1: 语音交互的优势
优势1:信息传递效率高
百度语音开放平台的研究结果显示,相比于传统的键盘输入,语音输入方式在速度及准确率方面更具优势。利用语音输入英语和普通话的速度分别是传统输入方式的3.24倍和3.21倍,信息传递效率进一步可拆分为4类:
- 检索高效 :针对复杂的输入词,尤其是在输入方式不便的场景下,语音交互更高效。例如电视场景下进行电影搜索。
- 跨空间便捷 :远场语音交互可以跨3~5米进行交流,针对需要跨空间的操作,语音交互更高效,例如:智能家居控制。
- 跨场景便捷 :语音交互的潜在好处时可以根据说话内容自动判断意图场景,在需要频繁跨场景交互的场景下语音交互更高效。
- 支持组合指令 :语音交互可以一次性下达多条指令,然后分别执行,在需要支持多意图同时传递的场景下语音交互更高效。假设你今晚想要看一部电影,你可以选择说:“播放刘德华的电影电影要四星以上并且是免费观看的。”
优势2:解放双手和双眼
通过语言交互可以将手和眼睛空起来处理其他事情,在需要多感官协同的场景下效率更高。例如:车载场景通过语音点播音乐,医疗场景医生在沟通病情的同时记录病历,工业场景在双手占用的同时下达指令。
优势3:使用门槛低
- 非文字使用者友好 :人类是先有语音再有文字,每个人都会说话但有一部分人不会写字,针对老人、小孩、失明的人群,无法使用文字交互,语音交互会为其带来极大的便利。
- 学习成本低 :语音交互更自然,在非复杂场景下,语音交互比界面交互更自然,上手成本更低。
优势4:传递声学信息
- 声纹识人 :通过声纹可以进行身份判断,并且可以在下达指令的同时进行身份判断,效率更高。同时声音还可以判断性别、年龄层、情绪等信息。
- 声音传递情感 :声音交互可以传递情感,因此在有情感诉求的场景下,声音是一个很好的选择。
PART 2:语音交互的劣势
劣势1:信息接收效率低
语音输出是线性的,当别人说话时,你可能得等全部说完后才能理解,无法像文字一样可以跳过阅读;语音交互也会增加用户的记忆负担,尤其是面临多项选择并且选项内容较长时。
因此它无法同时输出很多内容,在接受信息和多选择交互时,视觉具有更大的优势,声音的效率不高。总结来讲,语音交互针对单向指令是更有效的,而双向交互不是很有效。
劣势2:嘈杂环境下语音识别精度降低
语音识别需要清晰的识别出人声,包括将人声和环境声进行分离,将人声和人声进行分离。嘈杂环境使得人声的提取变得非常困难,尤其是针对远场语音交互,噪音的问题更加突出。
目前业内普遍使用麦克风阵列硬件和相关算法来优化该问题,但是无法完全解决,例如远场安静环境下语音识别准确率能达到95%,但是在嘈杂环境下仅能达到80%出头。但是随着技术的进度,嘈杂环境下的远场语音识别准确度也肯定会逐步完提升。
劣势3:公开环境下语音交互具有心理负担
语音交互的心理障碍是用户不能预设和预先判断。在同一情况下,不同的人可能会产生完全不同的行为和期望。这给设计者带来了很大的麻烦,也给用户带来了不确定性。从心理体验来看,没有多少人愿意对着机器说话,因为有可能会得到毫无感情甚至是错误的反应
3. 语音交互适合什么场景和设备?
我们判断什么场景和设备适合增加语音交互,根据语音交互的优劣势分析,得出以下加分项和减分项,为了简单起见,每个得分享赋予相同的权重,然后计算综合得分,将适用程度划分为高、中、低3档,分别记2、1、0分。
原则1: 每个设备类型仅考虑起本身的功能,不考虑因为入口性质附加的额外功能,例如智能音箱,现在除了音箱属性,被赋予了天气、智能家居等其他属性。未来形态下家庭语音入口会分布式的,智能音箱被赋予的生活助手的角色也会被剥离。
原则2: 设备的功能考量时会考虑现在还不具备但是以后会延展的相关功能,例如冰箱,支持查询冰箱内的物品情况。
加分项:
- 需要复杂的信息输入:输入指令不能被穷举,则得分最高,如果仅简单的输入指令,则得分低;
- 使用对象双手或双眼被占用;
- 使用对象为非文字使用者:如果使用人群里老人、小孩和失明人群较多,则得分高,反之得分低;
- 需要跨短距离空间的操作:如果有实体按键,则得分高,如果可远程遥控则得分次之,而且皆无,则不得分;
- 原信息输入的工具比较受限:输入方式的便利程度触屏>遥控>按钮;
- 需要跨意图指令输入:如果需要同时或者相继发出不同意图的指令则得分高,反之得分低;
- 使用频次:基本每天都要使用得分最高,每周3次左右次之,低于每周一次不得分;
- 设备与声音的关联度:如果设备本身就是播放多媒体内容的得分高,其他的不得分;
- 需要声音传递额外信息:例如声纹、发音评测。
减分项:
- 环境私密程度低:例如办公场景;
- 环境嘈杂:例如商场场景;
- 涉及到多层次交互(触屏可弥补):例如点外卖;
- 涉及到多条目选择(触屏可弥补):例如购物;
- 涉及到重要/隐私信息传达(屏幕可弥补):例如取款机。
下表为各的场景和设备适合语音化的得分:
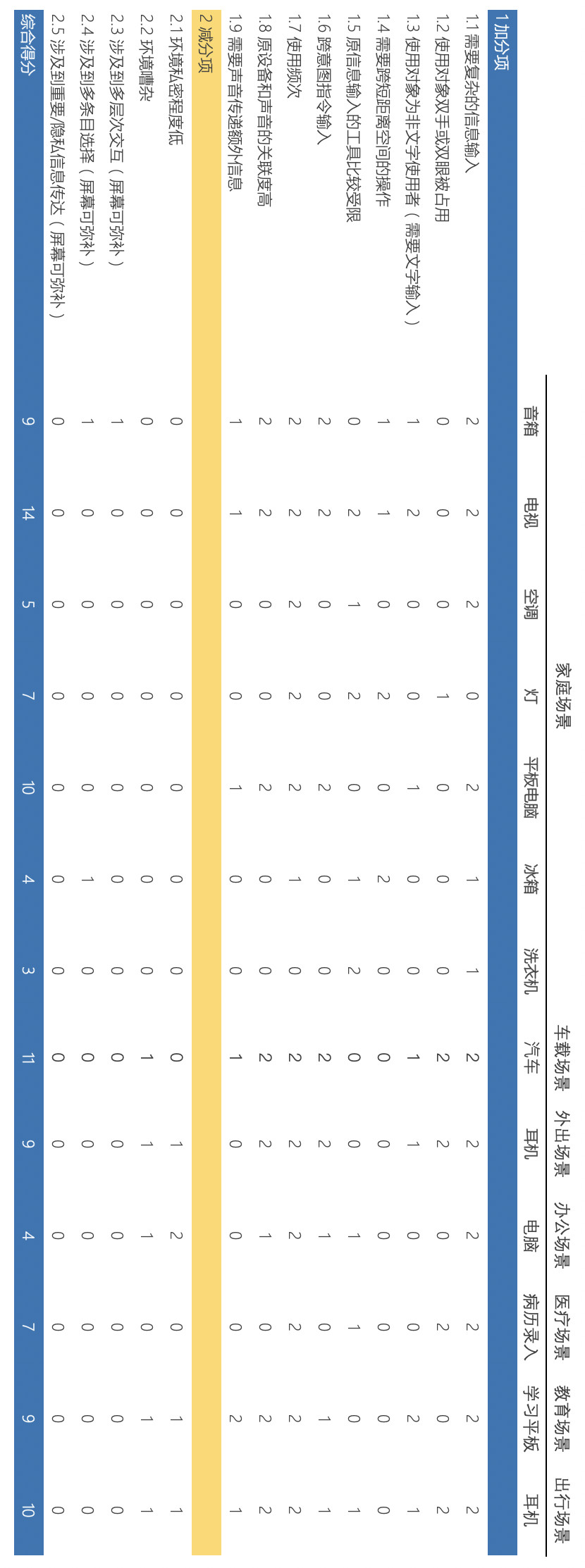
(1)家居场景
家庭环境比较封闭和私密,并且噪音少,是实现语音交互的很好环境。
- 电视 :机顶盒视为和电视同类,电视本身普及率及使用频次高,生态内容丰富使得其操作相对复杂,但又受限于遥控器这种低效的输入方式,使得电视成为最适合进行语音改造的设备,但是受囿于价格昂贵,尝鲜门槛高,所以改造的节奏相对较慢,但是新一代的电视语音化肯定是不可阻挡的趋势。
- 平板 :市面上目前流行的带屏音箱,更合适的说法应该是语音平板。
- 音箱 :音箱因为其低廉的成本(无需屏幕和视频资源)而率先引爆市场。
- 灯 :虽然指令简单,但是因其操作频繁且需要起身走到面前操作,跨空间成本高,使得灯具被语音化的诉求也较高。但是灯最适合的语音化是本地离线指令,也即通过“开灯”、”关灯”本地直接识别并控制灯具,无需加唤醒词,也无需先传到云端,云端处理完再传到本地,更简洁更快速。
- 空调 :空调因此相对高频的使用和较为复杂的指令,和灯具类似具备一定的语音化必要。
- 冰箱 :基本没有语音化必要,除非冰箱承载的功能做了极大延展,例如冰箱增加屏幕,同时作为餐厅的电视使用,那么其语音化的必要性与电视一致。
- 洗衣机 :基本没有语音化必要。
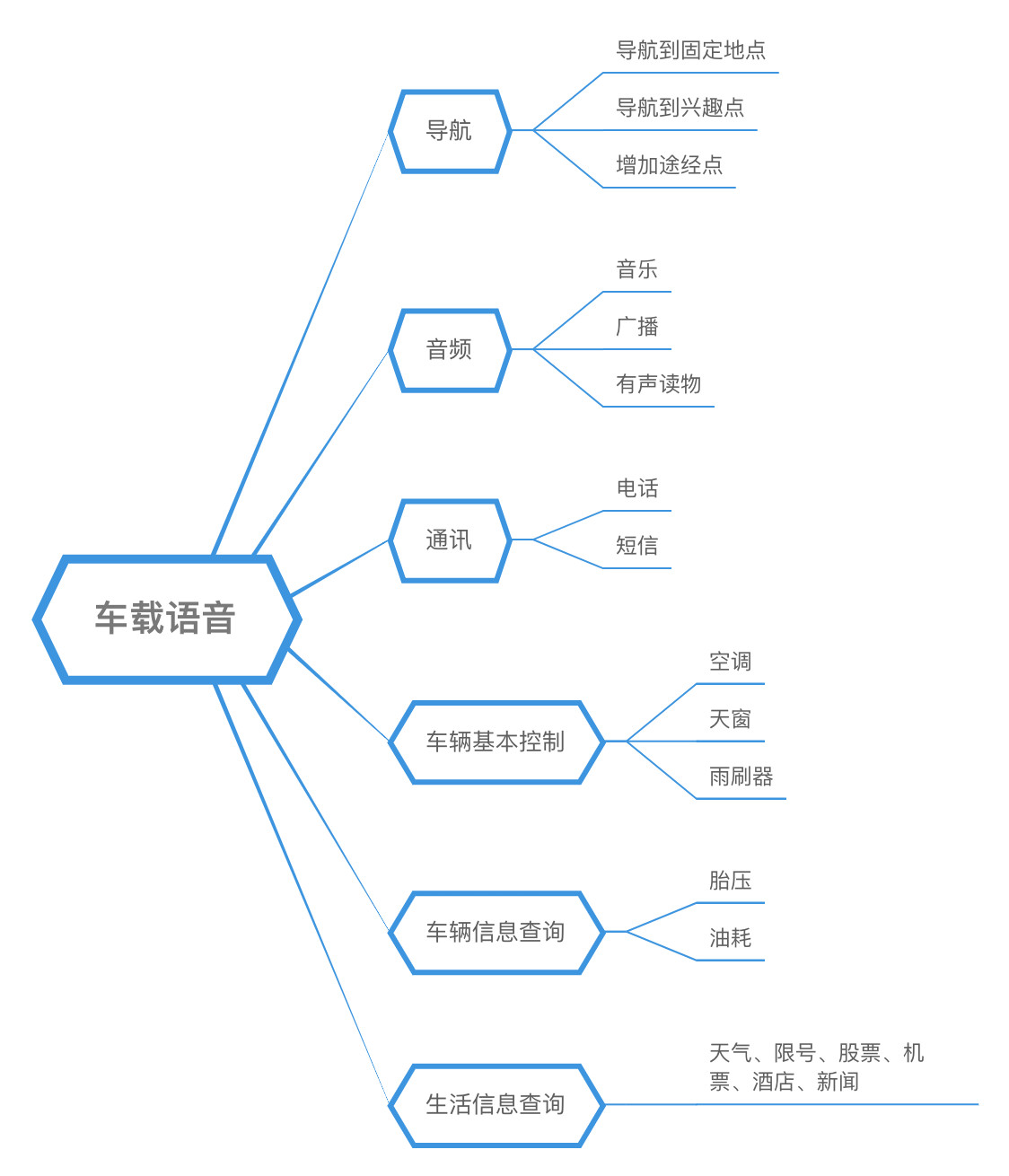
(2)车载场景
随着车联网和智能汽车的兴起,越来越多的功能被搭载在车机上。层出不穷的功能和日趋复杂的界面形成了对驾驶者注意力的争夺,新的矛盾由此诞生。车载语音技术的独特优势——帮助驾驶者降低对车内设备的操作依赖,增加驾驶安全系数。
车载场景相对比较私密,但是噪音相比家庭场景较高,尤其是当开窗之后风噪更大。但是因为开车时手和眼睛都被占用,语音成为交互的最佳选择,如接听电话、开关车窗、广播音乐、路线导航等语音指令,这就使得驾驶更加安全,可以更专注于路况。
车载常用语音功能如下:
(3)医疗场景
病历录入 :语音识别在医疗中的应用主要集中在直接将语音转成结构化电子病历,方便医生随时查阅,大大减轻了工作量。可以为医生节省手写病历的时间,同时也可以为医患纠纷提供材料佐证。
语音识别技术已经在以美国为首的西方国家成功运用到医院放射科、病理科、急诊室等部门中,临床中使用语音识别录入的比例已达到20%以上,并能够明显降低医生工作强度,提高工作效率,降低了医院日常运作成本。医疗业务营收占全球最大的语音技术公司Nuance全部营收的50%。
(4)企业场景
智能客服 :智能客服分为语音呼叫中心和在线客服两块来看。在客户服务行业,当用户请求接入后,先由智能客服机器人解答80%的常见问题,剩下20%复杂问题再由真人专家客服来回答解决。智能客服机器人创造的整套流程已经完全改变了整个客服行业的劳动力结构和工作方式。
- 目前,中国大约有500万全职客服,以年平均工资6万计算,再加上硬件设备和基础设施,整体规模约4000亿人民币。按照40-50%的替代比例,并排除场地、设备等基础设施以及甲方预算缩减,大概会有200-300亿规模留给智能客服公司。
- AI对企业服务市场的变革并不仅限于客服场景,以企业和用户沟通为桥梁和入口,智能客服公司可以延伸到营销、销售等重要的企业服务外部场景,从交互方式、流程优化、数据分析等角度推动企业外部服务的全面智能化,从而释放100-200亿的原有营销、销售等市场规模。
- 除了取代部分人工的客服机器人,AI也在变革企业传统的线下客服交互方式。随着智能设备、物联网的普及,各种设备也将成为企业服务客户的入口和新兴场景,智能客服公司、尤其是AI公司有机会在千亿智能设备交互市场中分得200-300亿规模。
(5)教育场景
语音平板 :在少儿教育场景,语音可以发挥的空间会非常大,一方面少儿的文字学习还没有非常完善,因此在信息录入和互动方面,语言是更低门槛的交互选择,另一方面,语音可以进行中英文发音的测评和纠正,对少儿的学习成长价值更大。
- 互动语言学习:针对语言发音,进行实时评测和纠正,提升学习效果;
- 互动动画:在动画中插入场景化语音交互,寓教于乐,提升少儿的沉浸感。
(6)出行场景
智能耳机 :搭配工具来进行语音交互会使得私密性更强而且更加方便。耳机作为本身就是穿戴中的一种产品,携带方便,决定了它有更多自然的使用场景,耳机这样私人且私密化很强的产品,无论人们是在上班通勤、户外运动还是在旅行时也能保持更高的使用率,戴在耳朵上的耳机,离人的语言器官很近,当你和耳机进行语音交互的时候,更像是和朋友交谈。
使用耳机来与手机的语音交互模式连接时,是不是也可以使用一些动作来唤醒它,例如:去敲击耳机,通过这类动作去唤醒可能会比喊它更加的自然,即使在公共场合也会避免尴尬出现。
(7)机器人
语言交互是人类日常最常用的交互方式,机器人自然要集成语音交互的功能。机器人分为消费级机器人和商户级机器人,消费级机器人使用语音传递情感和提升交互效率,商户级机器人使用语音传递品牌感和提升服务效率。
(8)安全与鉴权
声纹: 是无感知的身份识别,声纹识别的理论基础是每一个声音都具有独特的特征,通过该特征能将不同人的声音进行有效的区分。
美国研究机构已经表明在某些特点的环境下声纹可以用来作为有效的证据。并且美国联邦调查局对2000例与声纹相关的案件进行统计,利用声纹作为证据只有0.31%的错误率。目前利用声纹来区分不同人这项技术已经被广泛认可,并且在各个领域中都有应用。
声纹常常应用于刑侦破案、罪犯跟踪、国防监听、个性化应用等等,说话人确认技术常常应用于证券交易、银行交易、公安取证、个人电脑声控锁、汽车声控锁、身份证、信用卡的识别等。
4. 语音交互与其他交互方式的融合?
语音交互有着信息接收效率低、嘈杂环境识别精度低、公开环境心理负担的劣势,因此在很多场景下纯语音交互很受限,但是这些交互方式是可以通过其他交互进行弥补的。
毋庸置疑,在接下来的几年内肯定会有更多不同结合方式的产品出现。

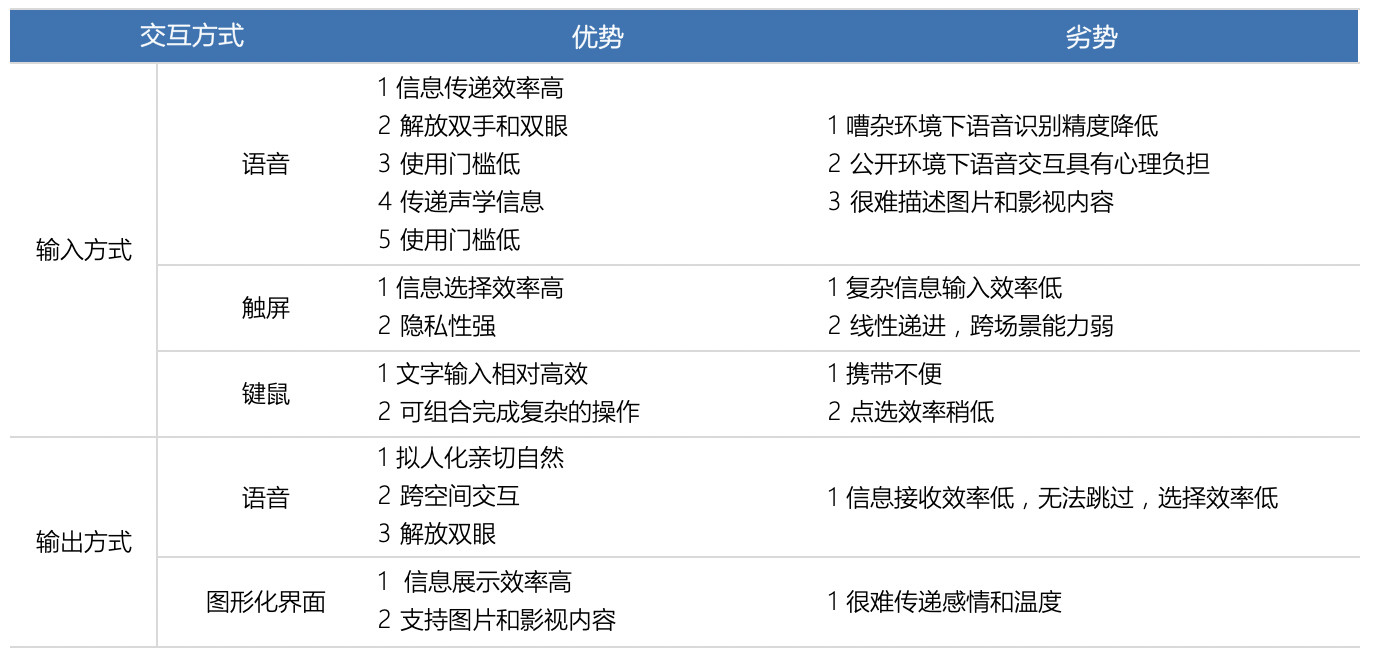
(1)语音输入/视觉化输出
近些年,市面上有许多产品合入了语音输入,其中有很多是有显示屏的产品。在这些产品上,我们允许用户语音输入,而用界面显示输出的信息。
语音智能电视也是一个很好的例子。它们没有能够支持复杂输入的硬件设备,而本身又有足够多的功能足以支撑自然语义查询。比如通过语音直接说“播放流浪地球”,要比用遥控器上的十字箭头方便多了。
语音智能屏幕是另外一个例子,从18年下半年语音智能屏幕开始流行,主要针对老人和小孩的人群,对老人的价值在于可以通过语音交互,搜索想看的影视内容,对儿童的价值,在于语音沟通、影视播控以及声音的评测。
实际上,那些有复杂功能,需要复杂输入,而这些输入都可以用语音命令代替,同时返回的结果不适合机读出来的系统,都适合使用语音作为输入方式,而用视觉作为输出方式。
(2)混合模式
许多设备都在朝着混合模式的方向发展,它们会将语音、物理输入和屏幕、语音输出结合。导航app就是一个将这些交互手段结合的典型例子。
用户能够触控拖动地图来查看,用物理按键或虚拟键盘输入。当驾车时,可以通过直接说目的地名称来开启导航,用这种方式用户可以不用将目光移向屏幕或用手来操作。语音输出可以输出导航的命令指示,而例如周围道路拥堵状况等较为难以描述的信息可以使用屏幕显示。
这是一种很好的输入输出结合方式,每种交互方式都将自己的优势发挥出来。整个导航系统会根据用户需求和信息的复杂程度来选择信息的呈现方式,一方面,用户在特定场景下可以不用手眼就能操作,而同时用户也能选择在另一些场景下使用屏幕。
但这种方式的设计还很少见,因为上述的方式是基于对用户的使用方式有深刻理解的基础上的。导航系统在汽车内使用语音还是一个比较明显的场景,但不是所有的产品都有一个明确的使用环境,所以判断什么情况下使用语音交互是比较困难的。
5. 语音交互的未来
虽然目前的语音识别技术已经能够让机器听懂大部分人类的声音,但离“贾维斯”这种假想的超级智能助理的交互能力还很远,语音识别技术的发展方向将从识别到感知认知。
趋势1:免唤醒交互
远场语音交互,出于意图识别考虑,增加唤醒词作为对话开始的条件,但是唤醒词也无形中增加了沟通的成本。尤其是在一些多轮次交互方案中,例如:你想看电影,主流程需要“我要看电影”-“播放第3个”-“全屏”-“快进3分钟”,如果每次都要唤醒,用户体验很差,部分情况反而不如遥控器效率高。因此在特定多流程场景下迫切需要免唤醒交互。
趋势2:离线语音识别
离线语音识别指的是在本地直接进行指令的识别和处理,而无需连接到云端,好处是一方面无需唤醒词,另一方面无需联网,速度快。针对灯、空调、电视等设备,采用离线指令识别体验更好,例如直接对设备说“开灯”和“关灯”可以快速实现台灯的开和关。
趋势3:多通道交互
IOT时代家庭的联网设备越来越多,但是体验提升有限,直到IOT有了语音AI的加持,彻底宣告AIOT时代的到来,通过语音设备可以控制联网设备,进一步促进了家庭智能设备的渗透和覆盖,2018年中国智能音箱销售量约2200万台,随着家庭智能设备的越来越多,用户的需求也逐步出现新的特征。
- 第1:需求往往都是非单一任务,而是多任务聚合;
- 第2:需要多设备之间的联动;
- 第3:服务状态可以持续性迁移,无论是跨时间还是空间。
多通道交互就是综合使用多种输入通道和输出通道,用最恰当的方式传递服务,满足用户需求。
通俗一点讲,多模态互动就是将智能设备的通道进行注册和管理,根据用户的需求,给不同的通道分配相应的任务,以期用最恰当的方式去满足用户需求。例如:将智能音箱和电视作为一个系统进行多通道交互,可以综合使用它们5个输入和输出通道。举个最简单的例子:当我问音箱天气的时候,可以将天气的图形通过电视进行显示和播报,更用户更直观的体验。
MCUI在家庭场景落地的最典型案例,就是智能音箱和机顶盒的组合,可以实现带屏智能音箱的所有功能,并且体验更佳。
- 一方面成本更低,一个无屏音箱100元以内,带屏智能音箱需要500元左右。
- 另一方面大屏观看体验更佳,针对儿童教育场景,大屏不容易造成近视,并且父母的可管控型更强,因此智能音箱+机顶盒的产品体验,以后一定会成为主流。
参考资料:Laura Klein,面对智能化的未来,设计师你准备好了么(语音交互篇)
作者:Jason,微信公众号:Smart_Byte。
本文由@Jason 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash, 基于CC0协议
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: