智能风控平台核心之风控决策引擎(二)
本文主要介绍了信贷风控策略的建设思路、以及决策引擎的主要功能。

适用阅读人群:互金产品人员、互金模型人员、互金研发人员
在之前的文章《风控决策引擎(一)》中,我只是对风控决策引擎的核心功能规则、评分卡、模型、表达式、决策流等模块做了简介。
大数据风控,大数据输入决策引擎通过规则、评分卡、模型、表达式、决策流等功能模块就能输出理想的风控结果了吗?
实际业务中的风控流程依靠这几个功能模块是无法完全达到风控目的,成熟的风控方案有一套严谨的策略体系,风控决策引擎要结合风控策略体系,最终才能达到风险控制的目标。
大数据风控通用流程主要为贷前、贷中、贷后全信贷生命周期风控,分别对应的评分卡有A卡 ( Application score card)申请评分卡、B卡(Behavior score card)行为评分卡、C卡(Collection score card)催收评分卡。
评分卡的开发需要丰富的数据支撑,在信贷业务初期由于数据不充分,则不具备评分卡的开发,这时候就会选择规则判断进行初期的风控。
信贷通用的风控都是包含了规则和评分卡两部分,贷前流行的风控策略流如下:
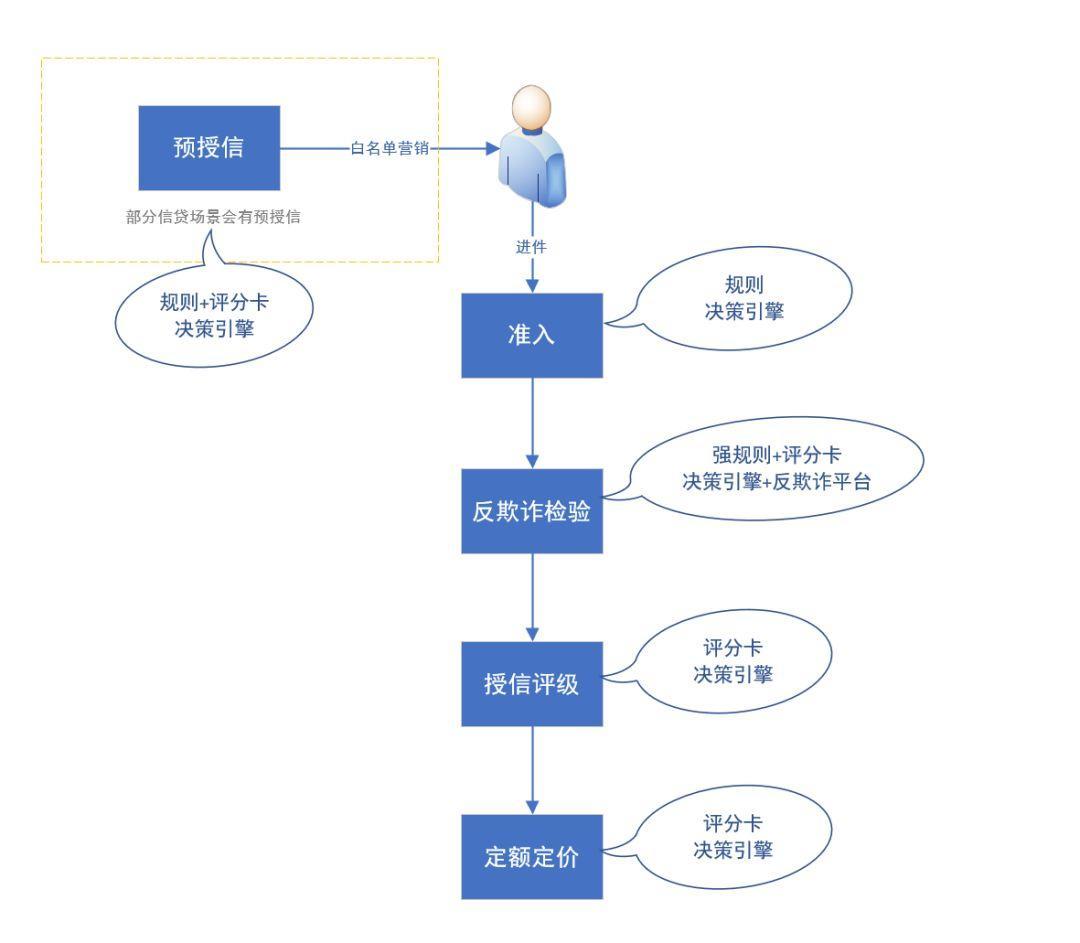
基于准入、反欺诈(黑名单)、信用评级、定额定价四部分构成,具体的信贷场景在此基础上也会有部分调整,在自有存量客户较大的时候,新上线信贷产品之前很多厂家都会在准入之前加入预授信策略。
无论是准入、反欺诈、授信评级中的规则还是评分卡,通常是都是通过决策引擎进行逻辑判断,在智能风控平台之决策引擎(一)中介绍了四个常用的决策引擎功能模块,其中决策流配置模块就是用来配置信贷风控策略流,评分卡模块配置评分卡模型进行封装成规则包、规则模块配置规则进行封装成规则包,在通过决策流配置模块配置风控流程。
信贷风控流程就是决策引擎对于传入数据的组合运算,有风控策略流程就有规则的优先级运算也就有数据传入的优先级概念,优先级制定的原则主要是从数据源、规则的强弱(强规则命中直接拒绝、弱规则需要组合判断决策)、数据成本、效率、数据积累等方面进行考虑:
自有数据源对应的规则优于三方数据源对应的的规则
自有数据源在接口请求、性能、价格等方面都优于三方数据源,如自有的黑名单库数据,在命中黑名单规则可以直接拒绝。
强规则(强规则命中直接拒绝)优于弱规则(弱规则需要组合判断决策)
很多决策引擎的性能伴随着规则数量的增加下降,考虑更好的利用决策引擎的资源,强规则决策优于弱规则决策。
例如命中前科拒绝这种强规则,应该优于命中多头借贷且命中逾期3次拒绝这种组合的弱规则。
低成本数据对应的规则优于高成本数据对应的规则
大数据风控,数据的费用在整个智能风控中占据着较重的比列,在制定的风控策略流程的时候,低成本规则优于高成本规则。
三方数据服务主要由查得、查询两种计费模式,其中查得是指三方数据返回有结果进行计费;
查询是指请求三方数据,不管三方数据是否返回结果就进行计费,因此查得对应的规则优于查询对应的规则。
效率高的规则优于效率低规则
有些规则比如规则甲只需要一个接口A就能做出决策,而规则乙则需要三个接口B/C/E才能做出决策,因为接口的请求是需要时间,这时候就需要考虑规则效率,效率高的由于效率低的规则。
需要积累数据的规则优于无需积累数据的规则
在模型冷启动的时候,有些变量作为后期模型潜在核心变量,需要尽可能多的收集这些数据,此时需要积累数据的规则优于无需积累数据的规则。
以上的优先级原则不都是固定不变的,很多规则优先级的制定都是基于几个原则的综合考虑。
由规则的优先级原则,对于风控决策引擎在决策运算时的功能要求是,能够对于决策流程命中拒绝结果后实现决策流程的决策终断以及决策继续,决策流程不仅可以在大的决策流上实现决策流程开关,而且也可以对小的支流某条规则实现决策流程的开关。
数据接入优先级确认,传入决策引擎进行规则、评分卡、模型的决策,此时还需考虑数据缺失时,数据缺失太多规则、评分卡等的风控也会失灵,那此情形下的决策引擎应该怎么处理呢?
通常规则类的策略,在命中数据缺失的时候,可以在规则中配置决策结果直接输出缺失的结果。
但是评分卡类的策略,如果在数据缺失时通过配置其得分,最后计算总得分,依据总分进行评分卡的结果决策,这样很难保证评分卡的效果。
例如评分卡中的变量丰富的时候,其中核心变量是不能允许缺失;但是如果决策引擎没有对应的判断机制,在核心变量缺失时,其他变量没有缺失同时其他变量的得分较高,此时拉高了整体的评分卡的得分,最后的得分做出决策为通过。实际该客户因为核心变量缺失需要通过人工审核,因此在这种情形下并不能准确的判断客户的征信情况。
那么决策引擎应该怎么去解决这个问题呢?
设计决策引擎产品下到规则集、评分卡的每一条决策判断,上到规则包、模型包的决策判断都需要进行数据信息值的计算,在决策引擎中的规则、评分卡配置上需要具备信息值的配置、信息值的阈值配置以及信息值的决策结果配置等。
决策引擎在进行规则的判断的时候,首先应该计算的是信息值,然后在进行策略的运算,通过对缺失值的管控,实现更精准的风控效果。
决策引擎主要的用户是模型策略人员,风控策略伴随着业务的发生,会进行不断地调整、迭代,同时不同的业务场景所使用的模型策略也是不同的,因此决策引擎还需要满足模型版本管理、模型对比的功能,可以更方便用户配置操作、支撑更多的业务场景。
模型的优化、迭代是需要丰富的历史数据作为支撑,这里的历史数据可以分为两部分:
- 传入决策引擎的元数据
- 决策引擎计算出来的结果数据包含规则、评分卡等数据。
数据在传入决策引擎进行计算后需要对元数据和结果数据进行存储,这里的存储也会存在两种方式:
- 缓存,这样可以避免同一个客户在规定的时间内重复调用三方数据,造成不必要的成本浪费;
- 存储所有的风控数据,便于后期模型的调优、迭代,同时也可以用于贷中、贷后的管理。数据存储的功能,更多的规划在决策引擎的配套产品接口管理平台中,在后面决策引擎配套产品介绍中会详细的介绍。
实际业务中,风控的结果输出,不仅仅只是“通过”、“拒绝”、“人工审核”,还会有很多详细的内容包含触发的规则、预警的规则等,这就要求需要一个详细的风控报告输出,以备人工审核的人员获取数据,这也是决策引擎配套的风控报告产品。
以上介绍了关于决策引擎的部分主要功能和风控策略流程的建设思路,应大家的要求我会在下一章中补充介绍复杂规则、复杂评分卡的产品设计,敬请期待。
作者:互金杂货铺,微信号:zjlove778。
本文由 @互金杂货铺 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自unsplash,基于CC0协议
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: