HTTP API 认证授权术
 我们知道,HTTP是无状态的,所以,当我们需要获得用户是否在登录的状态时,我们需要检查用户的登录状态,一般来说,用户的登录成功后,服务器会发一个登录凭证(又被叫作Token),就像你去访问某个公司,在前台被认证过合法后,这个公司的前台会给你的一个访客卡一样,之后,你在这个公司内去到哪都用这个访客卡来开门,而不再校验你是哪一个人。在计算机的世界里,这个登录凭证的相关数据会放在两种地方,一个地方在用户端,以Cookie的方式(一般不会放在浏览器的Local
Storage,因为这很容易出现登录凭证被XSS攻击),另一个地方是放在服务器端,又叫Session的方式(SessonID存于Cookie)。
我们知道,HTTP是无状态的,所以,当我们需要获得用户是否在登录的状态时,我们需要检查用户的登录状态,一般来说,用户的登录成功后,服务器会发一个登录凭证(又被叫作Token),就像你去访问某个公司,在前台被认证过合法后,这个公司的前台会给你的一个访客卡一样,之后,你在这个公司内去到哪都用这个访客卡来开门,而不再校验你是哪一个人。在计算机的世界里,这个登录凭证的相关数据会放在两种地方,一个地方在用户端,以Cookie的方式(一般不会放在浏览器的Local
Storage,因为这很容易出现登录凭证被XSS攻击),另一个地方是放在服务器端,又叫Session的方式(SessonID存于Cookie)。
但是,这个世界还是比较复杂的,除了用户访问,还有用户委托的第三方的应用,还有企业和企业间的调用,这里,我想把业内常用的一些 API认证技术相对系统地总结归纳一下,这样可以让大家更为全面的了解这些技术。 注意,这是一篇长文!
本篇文章会覆盖如下技术:
- HTTP Basic
- Digest Access
- App Secret Key + HMAC
- JWT - JSON Web Tokens
- OAuth 1.0 - 3 legged & 2 legged
- OAuth 2.0 - Authentication Code & Client Credential
HTTP Basic
HTTP Basic 是一个非常传统的API认证技术,也是一个比较简单的技术。这个技术也就是使用 username和 password
来进行登录。整个过程被定义在了 RFC 2617 中,也被描述在了
Wikipedia: Basic Access
Authentication
词条中,同时也可以参看 MDN HTTP Authentication
其技术原理如下:
- 把
username和password做成username:password的样子(用冒号分隔) - 进行Base64编码。
Base64("username:password")得到一个字符串(如:把haoel:coolshell进行base64 后可以得到aGFvZW86Y29vbHNoZWxsCg) - 把
aGFvZW86Y29vbHNoZWxsCg放到HTTP头中Authorization字段中,形成Authorization: Basic aGFvZW86Y29vbHNoZWxsCg,然后发送到服务端。 - 服务端如果没有在头里看到认证字段,则返回401错,以及一个个
[WWW-Authenticate](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/WWW-Authenticate): Basic Realm='HelloWorld'之类的头要求客户端进行认证。之后如果没有认证通过,则返回一个401错。如果服务端认证通过,那么会返回200。
我们可以看到,使用Base64的目的无非就是为了把一些特殊的字符给搞掉,这样就可以放在HTTP协议里传输了。而这种方式的问题最大的问题就是把用户名和口令放在网络上传,所以,一般要配合TLS/SSL的安全加密方式来使用。我们可以看到 JIRA Cloud 的API认证支持HTTP Basic 这样的方式。
但我们还是要知道,这种把用户名和密码同时放在公网上传输的方式有点不太好,因为Base64不是加密协议,保是编码协议,所以就算是有HTTPS作为安全保护,给人的感觉还是不放心。
Digest Access
中文称“HTTP 摘要认证”,最初被定义在了 RFC 2069 文档中(后来被 RFC 2617 引入了一系列安全增强的选项;“保护质量”(qop)、随机数计数器由客户端增加、以及客户生成的随机数)。
其基本思路是,请求方把用户名口令和域做一个MD5 - MD5(username:realm:password)
然后传给服务器,这样就不会在网上传用户名和口令了,但是,因为用户名和口令基本不会变,所以,这个MD5的字符串也是比较固定的,因此,这个认证过程在其中加入了两个事,一个是
nonce 另一个是 qop
- 首先,调用方发起一个普通的HTTP请求。比如:
GET /coolshell/admin/ HTTP/1.1 服务端自然不能认证能过,服务端返回401错误,并且在HTTP头里的
WWW-Authenticate包含如下信息:WWW-Authenticate: Digest realm="testrealm@host.com", qop="auth,auth-int", nonce="dcd98b7102dd2f0e8b11d0f600bfb0c093", opaque="5ccc069c403ebaf9f0171e9517f40e41"
其中的
nonce为服务器端生成的随机数,然后,客户端做HASH1=MD5(MD5(username:realm:password):nonce:cnonce),其中的cnonce为客户端生成的随机数,这样就可以使得整个MD5的结果是不一样的。如果
qop中包含了auth,那么还得做HASH2=MD5(method:digestURI)其中的method就是HTTP的请求方法(GET/POST…),digestURI是请求的URL。如果
qop中包含了auth-init,那么,得做HASH2=MD5(method:digestURI:MD5(entityBody))其中的entityBody就是HTTP请求的整个数据体。然后,得到
response = MD5(HASH1:nonce:nonceCount:cnonce:qop:HASH2)如果没有qop则response = MD5(HA1:nonce:HA2)最后,我们的客户端对服务端发起如下请求—— 注意HTTP头的
Authorization: Digest ...GET /dir/index.html HTTP/1.0 Host: localhost Authorization: Digest username="Mufasa", realm="testrealm@host.com", nonce="dcd98b7102dd2f0e8b11d0f600bfb0c093", uri="%2Fcoolshell%2Fadmin", qop=auth, nc=00000001, cnonce="0a4f113b", response="6629fae49393a05397450978507c4ef1", opaque="5ccc069c403ebaf9f0171e9517f40e41"
维基百科上的 Wikipedia: Digest access authentication 词条非常详细地描述了这个细节。
摘要认证这个方式会比之前的方式要好一些,因为没有在网上传递用户的密码,而只是把密码的MD5传送过去,相对会比较安全,而且,其并不需要是否TLS/SSL的安全链接。但是, 别看这个算法这么复杂,最后你可以发现,整个过程其实关键是用户的password,这个password如果不够得杂,其实是可以被暴力破解的,而且,整个过程是非常容易受到中间人攻击 ——比如一个中间人告诉客户端需要一个 。
App Secret Key + HMAC
先说HMAC技术,这个东西来自于MAC - Message Authentication Code,是一种用于给消息签名的技术,也就是说,我们怕消息在传递的过程中被人修改,所以,我们需要用对消息进行一个MAC算法,得到一个摘要字串,然后,接收方得到消息后,进行同样的计算,然后比较这个MAC字符串,如果一致,则表明没有被修改过(整个过程参看下图)。而HMAC - Hash-based Authenticsation Code,指的是利用Hash技术完成这一工作,比如:SHA-256算法。
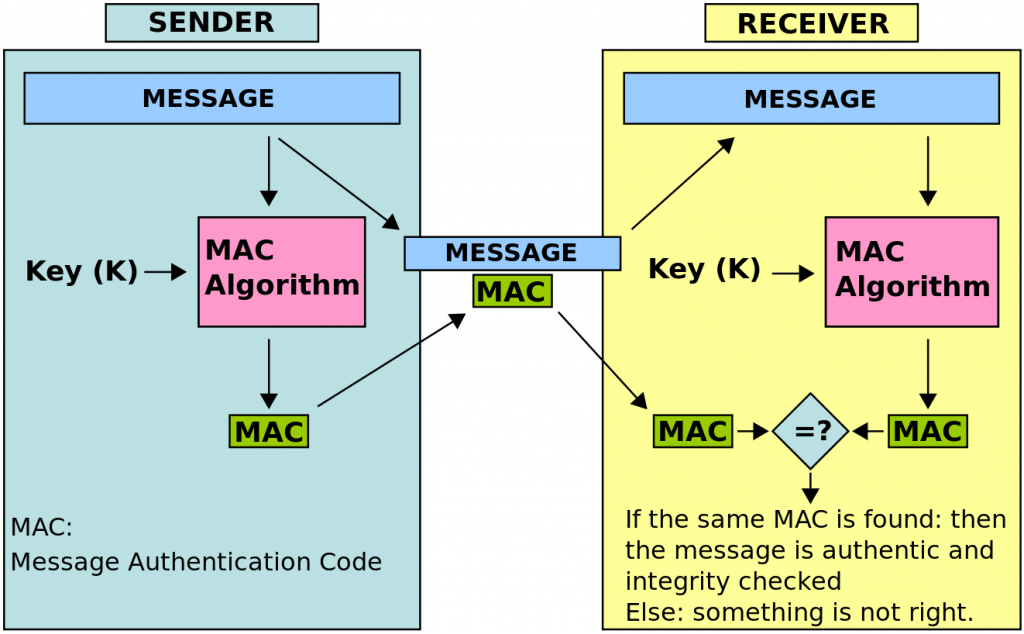
(图片来自 Wikipedia - MAC 词条 )
我们再来说App ID,这个东西跟验证没有关系,只是用来区分,是谁来调用API的,就像我们每个人的身份证一样,只是用来标注不同的人,不是用来做身份认证的。与前面的不同之处是,这里,我们需要用App ID 来映射一个用于加密的密钥,这样一来,我们就可以在服务器端进行相关的管理,我们可以生成若干个密钥对(AppID, AppSecret),并可以有更细粒度的操作权限管理。
把AppID和HMAC用于API认证,目前来说,玩得最好最专业的应该是AWS了,我们可以通过S3的API请求签名文档看到AWS是怎么玩的。整个过程还是非常复杂的,可以通过下面的图片流程看个大概。基本上来说,分成如下几个步骤:
- 把HTTP的请求(方法、URI、查询字串、头、签名头,body)打个包叫
CanonicalRequest,作个SHA-256的签名,然后再做一个base16的编码 - 把上面的这个签名和签名算法
AWS4-HMAC-SHA256、时间戳、Scop,再打一个包,叫StringToSign。 - 准备签名,用
AWSSecretAccessKey来对日期签一个DataKey,再用DataKey对要操作的Region签一个DataRegionKey,再对相关的服务签一个DataRegionServiceKey,最后得到SigningKey. - 用第三步的
SigningKey来对第二步的StringToSign签名。

最后,发出HTTP Request时,在HTTP头的 Authorization字段中放入如下的信息:
Authorization: AWS4-HMAC-SHA256
Credential=AKIDEXAMPLE/20150830/us-east-1/iam/aws4_request,
SignedHeaders=content-type;host;x-amz-date,
Signature=5d672d79c15b13162d9279b0855cfba6789a8edb4c82c400e06b5924a6f2b5d7
其中的 AKIDEXAMPLE 是 AWS Access Key ID, 也就是所谓的 AppID,服务器端会根据这个AppID来查相关的 Secret
Access Key,然后再验证签名。如果,你对这个过程有点没看懂的话,你可以读一读这篇文章——《Amazon S3 Rest API with
curl》这篇文章里有好些代码,代码应该是最有细节也是最准确的了。
这种认证的方式好处在于,AppID和AppSecretKey,是由服务器的系统开出的,所以,是可以被管理的,AWS的IAM就是相关的管理,其管理了用户、权限和其对应的AppID和AppSecretKey。但是不好的地方在于,这个东西没有标准
,所以,各家的实现很不一致。比如: Acquia 的 HMAC,微信的签名算法
(这里,我们需要说明一下,微信的API没有遵循HTTP协议的标准,把认证信息放在HTTP 头的 Authorization 里,而是放在body里)
JWT - JSON Web Tokens
JWT是一个比较标准的认证解决方案,这个技术在Java圈里应该用的是非常普遍的。JWT签名也是一种MAC(Message Authentication Code)的方法。JWT的签名流程一般是下面这个样子:
- 用户使用用户名和口令到认证服务器上请求认证。
- 认证服务器验证用户名和口令后,以服务器端生成JWT Token,这个token的生成过程如下:
- 认证服务器还会生成一个 Secret Key(密钥)
- 对JWT Header和 JWT Payload分别求Base64。在Payload可能包括了用户的抽象ID和的过期时间。
- 用密钥对JWT签名
HMAC-SHA256(SecertKey, Base64UrlEncode(JWT-Header)+'.'+Base64UrlEncode(JWT-Payload));
- 然后把
base64(header).base64(payload).signature作为 JWT token返回客户端。 - 客户端使用JWT Token向应用服务器发送相关的请求。这个JWT Token就像一个临时用户权证一样。
当应用服务器收到请求后:
- 应用服务会检查 JWT Token,确认签名是正确的。
- 然而,因为只有认证服务器有这个用户的Secret Key(密钥),所以,应用服务器得把JWT Token传给认证服务器。
- 认证服务器通过JWT Payload 解出用户的抽象ID,然后通过抽象ID查到登录时生成的Secret Key,然后再来检查一下签名。
- 认证服务器检查通过后,应用服务就可以认为这是合法请求了。
我们可以看以,上面的这个过程,是在认证服务器上为用户动态生成 Secret Key的,应用服务在验签的时候,需要到认证服务器上去签,这个过程增加了一些网络调用,所以,JWT除了支持HMAC- SHA256的算法外,还支持RSA的非对称加密的算法。
使用RSA非对称算法,在认证服务器这边放一个私钥,在应用服务器那边放一个公钥,认证服务器使用私钥加密,应用服务器使用公钥解密,这样一来,就不需要应用服务器向认证服务器请求了,但是,RSA是一个很慢的算法,所以,虽然你省了网络调用,但是却费了CPU,尤其是Header和Payload比较长的时候。所以,一种比较好的玩法是,如果我们把header 和 payload简单地做SHA256,这会很快,然后,我们用RSA加密这个SHA256出来的字符串,这样一来,RSA算法就比较快了,而我们也做到了使用RSA签名的目的。
最后,我们只需要使用一个机制在认证服务器和应用服务器之间定期地换一下公钥私钥对就好了。
这里强烈建议全文阅读 Anglar 大学的 《JSW:The Complete Guide to JSON Web Tokens》
OAuth 1.0
OAuth也是一个API认证的协议,这个协议最初在2006年由Twitter的工程师在开发OpenID实现的时候和社交书签网站Ma.gnolia时发现,没有一种好的委托授权协议,后来在2007年成立了一个OAuth小组,知道这个消息后,Google员工也加入进来,并完善有善了这个协议,在2007年底发布草案,过一年后,在2008年将OAuth放进了IETF作进一步的标准化工作,最后在2010年4月,正式发布OAuth 1.0,即:RFC 5849 (这个RFC比起TCP的那些来说读起来还是很轻松的),不过,如果你想了解其前身的草案,可以读一下 OAuth Core 1.0 Revision A ,我在下面做个大概的描述。
根据RFC 5849,可以看到 OAuth 的出现,目的是为了,用户为了想使用一个第三方的网络打印服务来打印他在某网站上的照片,但是,用户不想把自己的用户名和口令交给那个第三方的网络打印服务,但又想让那个第三方的网络打印服务来访问自己的照片,为了解决这个授权的问题,OAuth这个协议就出来了。
- 这个协议有三个角色:
- User(照片所有者-用户)
- Consumer(第三方照片打印服务)
- Service Provider(照片存储服务)
- 这个协义有三个阶段:
- Consumer获取Request Token
- Service Provider 认证用户并授权Consumer
- Consumer获取Access Token调用API访问用户的照片
整个授权过程是这样的:
- Consumer(第三方照片打印服务)需要先上Service Provider获得开发的 Consumer Key 和 Consumer Secret
- 当 User 访问 Consumer 时,Consumer 向 Service Provide 发起请求请求Request Token (需要对HTTP请求签名)
- Service Provide 验明 Consumer 是注册过的第三方服务商后,返回 Request Token(
oauth_token)和 Request Token Secret (oauth_token_secret) - Consumer 收到 Request Token 后,使用HTTP GET 请求把 User 切到 Service Provide 的认证页上(其中带上Request Token),让用户输入他的用户和口令。
- Service Provider 认证 User 成功后,跳回 Consumer,并返回 Request Token (
oauth_token)和 Verification Code(oauth_verifier) - 接下来就是签名请求,用Request Token 和 Verification Code 换取 Access Token (
oauth_token)和 Access Token Secret (oauth_token_secret) - 最后使用Access Token 访问用户授权访问的资源。
下图附上一个Yahoo!的流程图可以看到整个过程的相关细节。
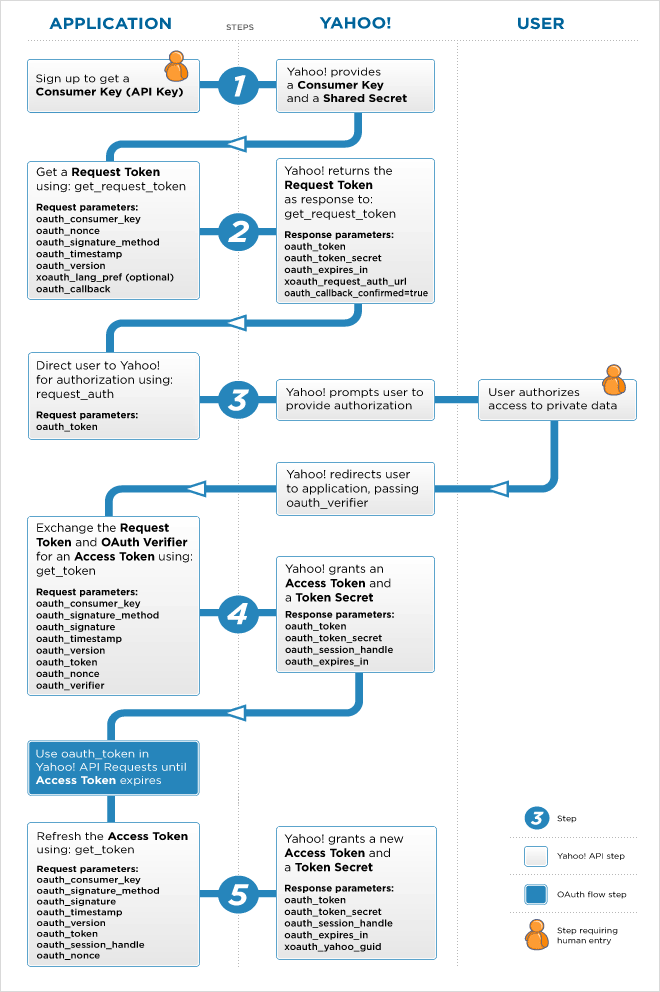
因为上面这个流程有三方:User,Consumer 和 Service Provide,所以,又叫 3-legged flow,三脚流程。OAuth 1.0 也有不需要用户参与的,只有Consumer 和 Service Provider 的, 也就是 2-legged flow 两脚流程,其中省掉了用户认证的事。整个过程如下所示:
- Consumer(第三方照片打印服务)需要先上Service Provider获得开发的 Consumer Key 和 Consumer Secret
- Consumer 向 Service Provide 发起请求请求Request Token (需要对HTTP请求签名)
- Service Provide 验明 Consumer 是注册过的第三方服务商后,返回 Request Token(
oauth_token)和 Request Token Secret (oauth_token_secret) - Consumer 收到 Request Token 后,直接换取 Access Token (
oauth_token)和 Access Token Secret (oauth_token_secret) - 最后使用Access Token 访问用户授权访问的资源。
最后,再来说一说OAuth中的签名。
- 我们可以看到,有两个密钥,一个是Consumer注册Service Provider时由Provider颁发的 Consumer Secret,另一个是 Token Secret。
- 签名密钥就是由这两具密钥拼接而成的,其中用
&作连接符。假设 Consumer Secret 为j49sk3j29djd而 Token Secret 为dh893hdasih9那个,签名密钥为:j49sk3j29djd&dh893hdasih9 - 在请求Request/Access Token的时候需要对整个HTTP请求进行签名(使用HMAC-SHA1和HMAC-RSA1签名算法),请求头中需要包括一些OAuth需要的字段,如:
- Consumer Key : 也就是所谓的AppID
- Token : Request Token 或 Access Token
- Signature Method :签名算法比如:HMAC-SHA1
- Timestamp :过期时间
- Nonce :随机字符串
- Call Back :回调URL
下图是整个签名的示意图:
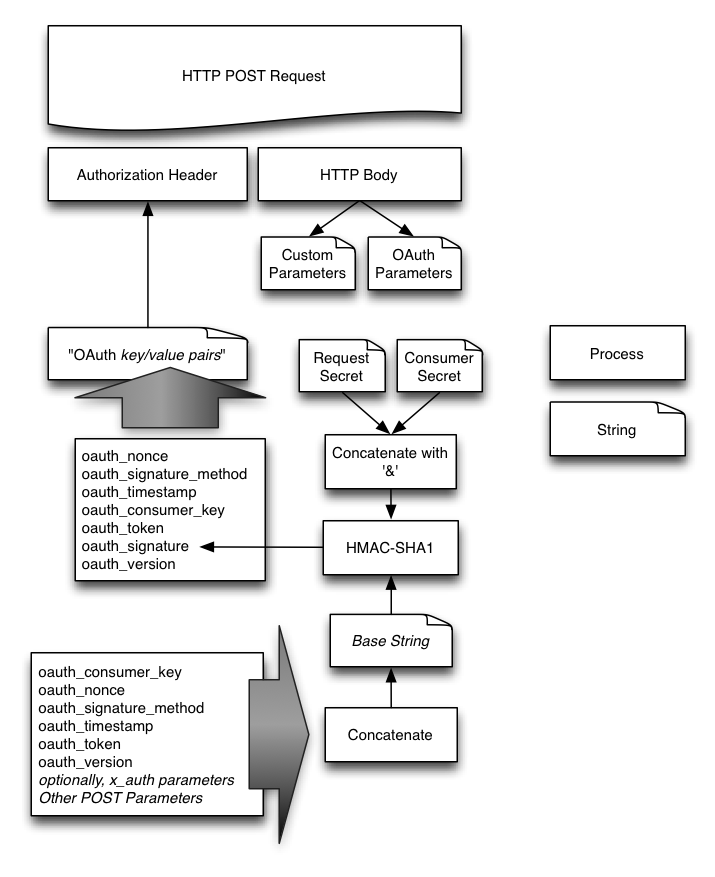
图片还是比较直观的,我就不多解释了。
OAuth 2.0
在前面,我们可以看到,从Digest Access, 到AppID+HMAC,再到JWT,再到OAuth 1.0,这些个API认证都是要向Client发一个密钥(或是用密码)然后用HASH或是RSA来签HTTP的请求, 这其中有个主要的原因是,以前的HTTP是明文传输,所以,在传输过程中很容易被篡改,于是才搞出来一套的安全签名机制 ,所以,这些个认证的玩法是可以在HTTP明文协议下玩的。
这种使用签名方式大家可以看到是比较复杂的,所以,对于开发者来说,也是很不友好的,在组织签名的那些HTTP报文的时候,各种,URLEncode和Base64,还要对Query的参数进行排序,然后有的方法还要层层签名,非常容易出错,另外,这种认证的安全粒度比较粗,授权也比较单一,对于有终端用户参与的移动端来说也有点不够。所以,在2012年的时候,OAuth 2.0 的 RFC 6749 正式放出。
OAuth 2.0依赖于TLS/SSL的链路加密技术(HTTPS),完全放弃了签名的方式,认证服务器再也不返回什么 token secret 的密钥了,所以,OAuth 2.0是完全不同于1.0 的,也是不兼容的 。目前,Facebook 的 Graph API 只支持OAuth 2.0协议,Google 和 Microsoft Azure 也支持Auth 2.0,国内的微信和支付宝也支持使用OAuth 2.0。
下面,我们来重点看一下OAuth 2.0的两个主要的Flow:
- 一个是Authorization Code Flow, 这个是 3 legged 的
- 一个是Client Credential Flow,这个是 2 legged 的。
Authorization Code Flow
Authorization Code 是最常使用的OAuth 2.0的授权许可类型,它适用于用户给第三方应用授权访问自己信息的场景。这个Flow也是OAuth 2.0四个Flow中我个人觉得最完整的一个Flow,其流程图如下所示。
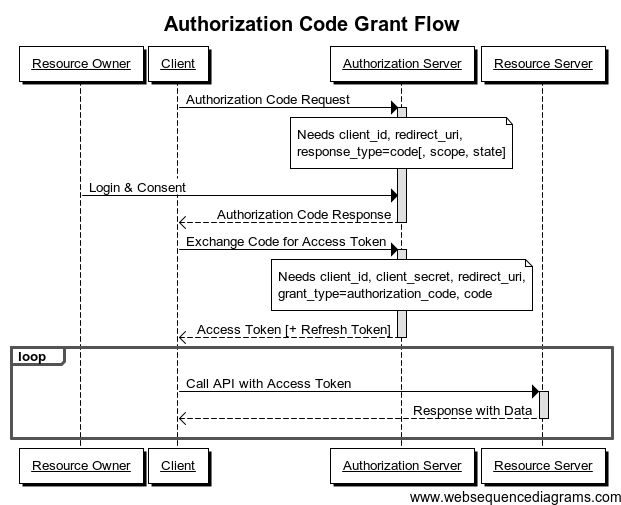
下面是对这个流程的一个细节上的解释:
1)当用户(Resource Owner)访问第三方应用(Client)的时候,第三方应用会把用户带到认证服务器(Authorization
Server)上去,主要请求的是 /authorize API,其中的请求方式如下所示。
https://login.authorization-server.com/authorize?
client_id=6731de76-14a6-49ae-97bc-6eba6914391e
&response_type=code
&redirect_uri=http%3A%2F%2Fexample-client.com%2Fcallback%2F
&scope=read
&state=xcoiv98CoolShell3kch
其中:
- *
client_id为第三方应用的App IDresponse_type=code为告诉认证服务器,我要走Authorization Code Flow。redirect_uri意思是我跳转回第三方应用的URLscope意是相关的权限state是一个随机的字符串,主要用于防CSRF攻击。
2)当Authorization Server收到这个URL请求后,其会通过 client_id来检查 redirect_uri和
scope是否合法,如果合法,则弹出一个页面,让用户授权(如果用户没有登录,则先让用户登录,登录完成后,出现授权访问页面)。
3)当用户授权同意访问以后,Authorization Server 会跳转回 Client ,并以其中加入一个 Authorization Code。 如下所示:
https://example-client.com/callback?
code=Yzk5ZDczMzRlNDEwYlrEqdFSBzjqfTG
&state=xcoiv98CoolShell3kch
我们可以看到,
- * 请流动的链接是第 1)步中的
redirect_uri- 其中的
state的值也和第 1)步的state一样。
- 其中的
4)接下来,Client 就可以使用 Authorization Code 获得 Access Token。其需要向 Authorization Server 发出如下请求。
POST /oauth/token HTTP/1.1
Host: authorization-server.com
code=Yzk5ZDczMzRlNDEwYlrEqdFSBzjqfTG
&grant_type=code
&redirect_uri=https%3A%2F%2Fexample-client.com%2Fcallback%2F
&client_id=6731de76-14a6-49ae-97bc-6eba6914391e
&client_secret=JqQX2PNo9bpM0uEihUPzyrh
5)如果没什么问题,Authorization 会返回如下信息。
{
"access_token": "iJKV1QiLCJhbGciOiJSUzI1NiI",
"refresh_token": "1KaPlrEqdFSBzjqfTGAMxZGU",
"token_type": "bearer",
"expires": 3600,
"id_token": "eyJ0eXAiOiJKV1QiLCJhbGciO.eyJhdWQiOiIyZDRkM..."
}
其中,
- *
access_token就是访问请求令牌了refresh_token用于刷新access_tokenid_token是JWT的token,其中一般会包含用户的OpenID
6)接下来就是用 Access Token 请求用户的资源了。
GET /v1/user/pictures
Host: https://example.resource.com
Authorization: Bearer iJKV1QiLCJhbGciOiJSUzI1NiI
Client Credential Flow
Client Credential 是一个简化版的API认证,主要是用于认证服务器到服务器的调用,也就是没有用户参与的的认证流程。下面是相关的流程图。

这个过程非常简单,本质上就是Client用自己的 client_id和 client_secret向Authorization Server 要一个
Access Token,然后使用Access Token访问相关的资源。
请求示例
POST /token HTTP/1.1
Host: server.example.com
Content-Type: application/x-www-form-urlencoded
grant_type=client_credentials
&client_id=czZCaGRSa3F0Mzpn
&client_secret=7Fjfp0ZBr1KtDRbnfVdmIw
返回示例
{
"access_token":"MTQ0NjJkZmQ5OTM2NDE1ZTZjNGZmZjI3",
"token_type":"bearer",
"expires_in":3600,
"refresh_token":"IwOGYzYTlmM2YxOTQ5MGE3YmNmMDFkNTVk",
"scope":"create"
}
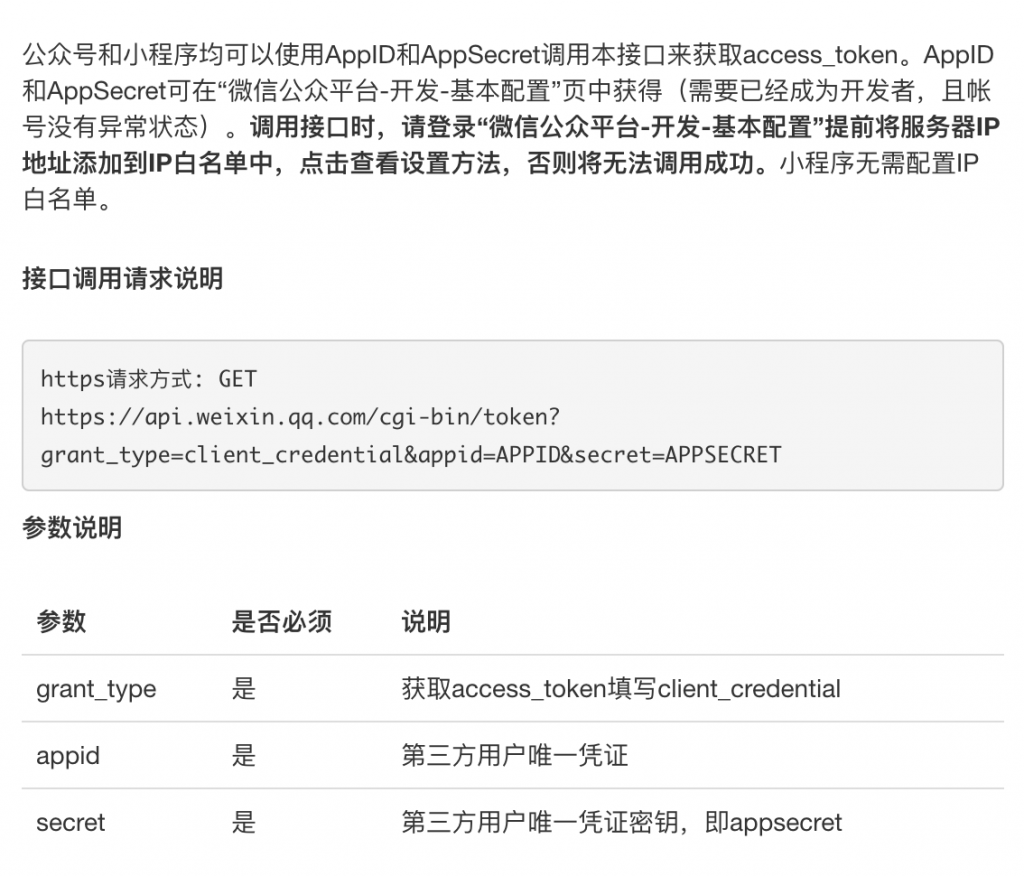
这里,容我多扯一句,微信公从平台的开发文档中,使用了OAuth 2.0 的 Client Credentials的方式(参看文档“微信公众号获取access token”),我截了个图如下所谓。我们可以看到, 微信公众号使用的是GET方式的请求,把AppID和AppSecret放在了URL中,虽然这也符合OAuth 2.0,但是并不好,因为大多数网关代理会把整个URI请求记到日志中。我们只要脑补一下腾讯的网关的Access Log,里面的日志一定会有很多的各个用户的AppID和AppSecret……
小结
讲了这么多,我们来小结一下(下面的小结可能会有点散)
两个概念和三个术语
- 区分两个概念:Authentication(认证) 和 Authorization (授权),前者是证明请求者是身份,就像身份证一样,后者是为了获得权限。身份是区别于别人的证明,而权限是证明自己的特权。Authentication为了证明操作的这个人就是他本人,需要提供密码、短信验证码,甚至人脸识别。Authorization 则是不需要在所有的请求都需要验人,是在经过Authorization后得到一个Token,这就是Authorization。就像护照和签证一样。
- 区分三个概念:编码Base64Encode、签名HMAC、加密RSA。编码是为了更的传输,等同于明文,签名是为了信息不能被篡改,加密是为了不让别人看到是什么信息。
明白一些初衷
- 使用复杂地HMAC哈希签名方式主要是应对当年没有TLS/SSL加密链路的情况。
- JWT把
uid放在 Token中目的是为了去掉状态,但不能让用户修改,所以需要签名。 - OAuth 1.0区分了两个事,一个是第三方的Client,一个是真正的用户,其先拿Request Token,再换Access Token的方法主要是为了把第三方应用和用户区分开来。
- 用户的Password是用户自己设置的,复杂度不可控,服务端颁发的Serect会很复杂,但主要目的是为了容易管理,可以随时注销掉。
- OAuth 协议有比所有认证协议有更为灵活完善的配置,如果使用AppID/AppSecret签名的方式,又需要做到可以有不同的权限和可以随时注销,那么你得开发一个像AWS的IAM这样的账号和密钥对管理的系统。
相关的注意事项
- 无论是哪种方式,我们都应该遵循HTTP的规范,把认证信息放在
AuthorizationHTTP 头中。 - 不要使用GET的方式在URL中放入secret之类的东西,因为很多proxy或gateway的软件会把整个URL记在Access Log文件中。
- 密钥Secret相当于Password,但他是用来加密的,最好不要在网络上传输,如果要传输,最好使用TLS/SSL的安全链路。
- HMAC中无论是MD5还是SHA1/SHA2,其计算都是非常快的,RSA的非对称加密是比较耗CPU的,尤其是要加密的字符串很长的时候。
- 最好不要在程序中hard code 你的 Secret,因为在github上有很多黑客的软件在监视各种Secret,千万小心!这类的东西应该放在你的配置系统或是部署系统中,在程序启动时设置在配置文件或是环境变量中。
- 使用AppID/AppSecret,还是使用OAuth1.0a,还是OAuth2.0,还是使用JWT,我个人建议使用TLS/SSL下的OAuth 2.0。
- 密钥是需要被管理的,管理就是可以新增可以撤销,可以设置账户和相关的权限。最好密钥是可以被自动更换的。
- 认证授权服务器(Authorization Server)和应用服务器(App Server)最好分开。
(全文完)


关注CoolShell微信公众账号和微信小程序
(转载本站文章请注明作者和出处酷 壳 - CoolShell ,请勿用于任何商业用途)
——=== 访问酷壳404页面 寻找遗失儿童。 ===——
相关文章
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。





Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: