人工智能的3种人机语义形式
人工智能的发展走过了从机器智能到感知智能的阶段,正在迈向认知智能的阶段。然而由于人类复杂的语言系统,一问一答形式的人机交互已经满足不了用户的真实需求,机器必须学会处理人类复杂的语言。

随着语音识别、NLP等技术的成熟,多轮对话交互系统将成为人机交互的重要纽带和桥梁。
目前市场上人机对话交互主要分为三种类型:任务型、问答型、闲聊型。
任务型主要目的就是根据用户描述的问题,收集必要的参数信息以完成用户的任务;问答型主要通过模型的解析,匹配知识库的答案并提供给用户;闲聊型主要以调节情绪,在用户当下的使用场景,以贴近用户情感为目的,拉近用户的距离。
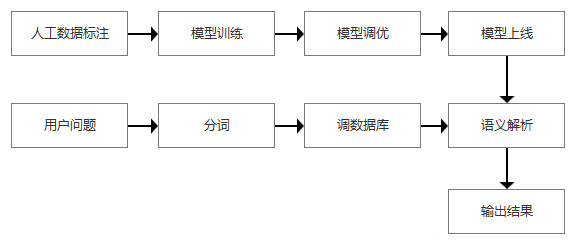
人机对话交互中,机器处理自然语言时需要用到不同的语义表达形式来处理。主要有分布式语义、框架式语义、模型式语义。
01 分布式语义
可以简单的理解为相似句模型解析。分布式语义需要标注大量的训练数据,大量的知识点会形成一个向量空间。当用户问题过来时,机器先将用户的问句进行分词,根据分词结果匹配词库,也可以将语义理解成向量,机器根据空间向量分布判断给出最优解。
日常在进行模型调优时,我们主要从数据和算法两个方面进行调优,再根据模型的正确率和召回率,找到最优的f值,给定模型的阈值。
目前大量的机器学习都用的是分布式语义,依靠数据来处理语义间的关系,但分布语义理解比较浅,很难处理深层的语义。
02 框架式语义
现在市场上有很多的语音助手产品,通过获取用户问题中的关键参数,然后将参数填入协议中,完成用户的任务操作。

例如“查一下7月1日上海到洛杉矶的航班”,这句话中我们需要获取到用户的四个信息槽位:
- 首先我们明确用户的场景,用户是想查飞机的航班信息,所以结果里肯定不能出现汽车、火车等场景;
- “7月1日”对应的肯定是时间的参数time,所以查询的结果里肯定是7月1日当天的一个航班信息;
- 用户的出发地是上海,目的地是洛杉矶,分别对应参数里的origin、destination,所以这边两个参数不能颠倒,不然查询的结果就不是用户真实想要的信息了。
可以看到框架式语义最重要的就是要识别语义中的参数信息,缺一个都不能完成用户的真实需求。所以在框架式语义中,框架识别和参数识别是非常重要的。
但用框架语义处理一些指代词等高级的语言或需要结合上下文理解的时候,会因为缺少某一个槽位,而丢失用户信息,所以现在很多框架语义配置时用了“平行槽位”。
首先明确在某一场景下,我们需要获取哪些槽位信息,当配置了平行槽位后,用户语义中缺少哪一个槽位信息,通过配置追问话术,将槽位信息补全,以完成用户的最终目的。
03 规则式语义
规则式语义就是将用户问句通过表达式的形式进行匹配,当满足规则要求时,给出结果回复。
要让用户问句能通过规则匹配问题,首先要明确走规则匹配逻辑要优先于相似句匹配。规则也需要获取问句中的实体信息,满足要求后,即可匹配上。
下面就举一个例子:

我们看这条规则由 () {} . & | : # 等标点符号,也有字段等信息组成的一条规则。看这规则会觉得比较乱,但细细分析,其实还是很简单的一条规则。
首先明确这个规则的意图,是一个打开动作,说明是一个指令。后面需要填写的槽位信息就是A股、港股、美股的槽位信息、最后一个就是栏目。所以可以确定这条规则就是一个“打开某只股票的个股资料”。
因为每个标点代表的意思是不同的,这就不细细说明了。所以当用户问句满足这个规则要求,就满足了这个规则对应的标准句,那用户就能得到该标准句对应的答案了。
不同的语义处理形式逻辑都不同,但最终的目的还是为了能完成用户下达的任务或操作。随着分词技术、实体抽取、NLU等技术的成熟,人机交互会更加和谐,处理效率会越来越高。
本文由 @vilionwang 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: