你真的懂数据分析吗?4个方面深入了解数据分析
“大数据”、“数据驱动”这些词汇,对沉浮在互联网的厂工们来说并不陌生,隔着屏幕,一边在源源不断地生产数据,一边在紧锣密鼓地收集解读数据。这些数据是奇妙的,它可以让人更加直观、清晰地认识世界,也可以指导人更加理智地做出决策。

数据分析目的有俩:
- 挖掘问题,定位原因,对症下药
- 验证假设,提供必要的数据支持
不能为了做数据分析而做,这是互联网小白甚至是白银段位产品汪也会犯的错误,你可能听到过这样的对话:
产品汪:“我们想看看跟贴用户里有多少是高活用户?”
几招过后,不想拉扯的数据分析师灵魂一问,“就先假设一个数,占比60%,你下一步的策略是什么?”
产品汪束手不及,瞪圆无辜的大眼,哑语。
此次谈判失败。
如果你只是想要一个值(日常指标监控不算在内),可以先假定,然后看看自己是否有进一步解决问题的思路,如果没有,说明这个问题你还没有想清楚,就不必大费周章做数据分析了,请给数据分析师减负。
数据流转/分析流程:
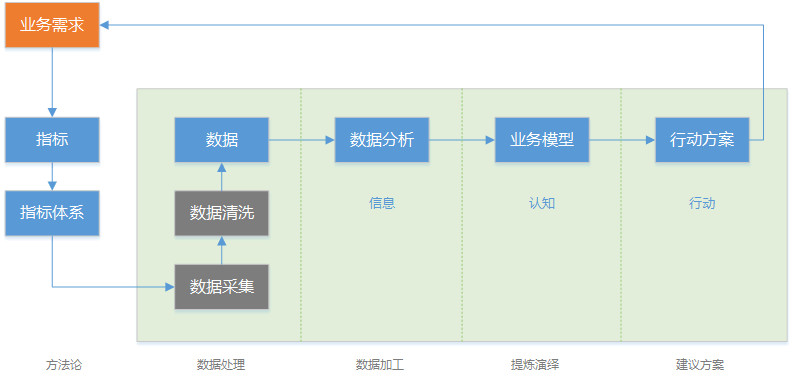
一、指标&指标体系
“好数据胜过大数据”,不要用装满数字的高压水枪把团队冲垮,那什么是好数据?
9个字简单概括: 比率、比较性、简单易懂。
- 比率:避免“抛开剂量谈毒性是耍流氓”的情况,在有一定统计学意义的统计量上看转化率,如看页面转化率比单纯看页面访问PV更有意义;看点击率比单纯看文章推荐量更有意义;
- 比较性:数据可以横向、纵向、环比等,能比较的数据才有意义;
- 简单易懂:如字。
不同的商业模式有不同的数据指标,热门的模式大致可以分为以下几类:
- 电子商务,如亚马逊、淘宝;
- 移动应用,如王者荣耀,今日头条;
- 媒体网站,如腾讯新闻网页版。
移动应用以新闻资讯app为例(如今日头条、网易新闻、腾讯视频等),简单阐述其指标体系。
宏观指标(水池理论)

我们把活跃用户当做一个活跃的蓄水池,每天每月有新的水进来(水的来源和水质都不同,有付费发行、免费发行、回流等),也有部分水流出(流失率),没有流出的水暂时停留在水池里,这一出一进维持着蓄水池的水量,也就是我们常提到的DAU/WAU/MAU。
流入>流出,看涨;流入<流出,看跌,道理浅显易懂。
产品发展期间,增长负责人也许会有担忧(特别是创业团队):“新增能够抵过流失吗?”
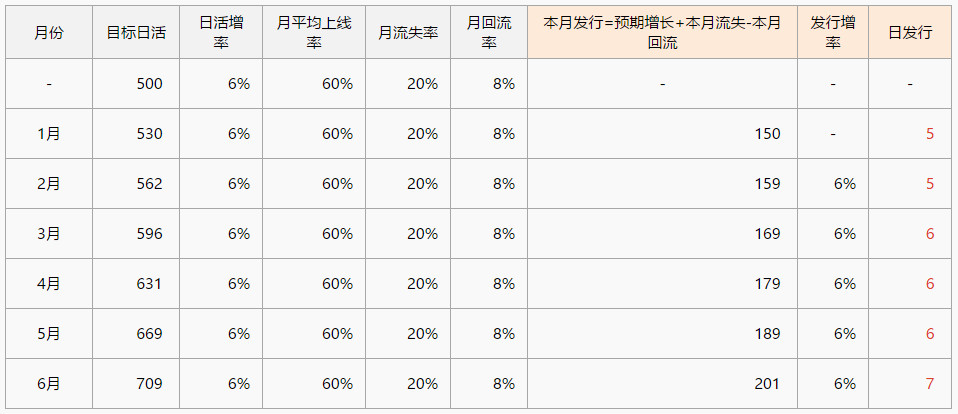
我们用水池理论来做一道数学题,已知数据:现存量用户500w,月平均上线率60%,月回流8%,月流失率20%,日活目标增率6%,即6个月后的日活目标是709w,请计算这半年每日发行量需达到多少?
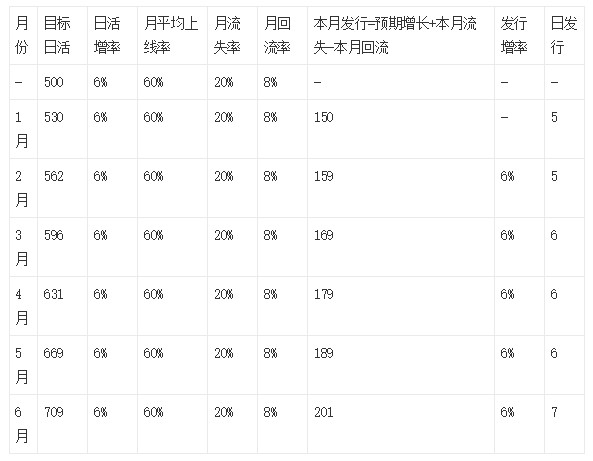
(备注:以上数据仅作理论说明,不做实际参考)
1月月发行=预期增长+本月流失-本月回流=500/60%6%+500/60%20%-500/60%*8%=150(w)
1月日发行=月发行/30=150/30=5(w)
假设发行投入稳定(即日发行相同,发行增率为0),如果日活要达到709w,那月回流率或月平均上线率要提高多少或者月流失率要降低多少?假设月流失率和月平均上线率均降低1%时,发行需要多提高多少才能维持目标?
日常数学题,以此类推。这是一种理想状态下的数据预估,实际情况要复杂得多,例如还包括活动营销、版本迭代的影响等。但对这些数据了然于心才能避免瞎子打靶的盲目行动。
几个指标之间的关系你应该了解,例如:
- 月发行=月流失+月期望增加-月回流
- 月流失=上月月活*本月月流失率
- 月期望增加=上月月活*(1+增长率)
- 回流率=回流的流失用户/日活用户
- 月平均上线率=(上线1天的人数1+上线2天的人数2+…上线30天的人数30)/(30日独立用户30)
- 其他
微观指标:
二、数据分析
基于了解了以上指标体系,怎么做数据分析?
- 了解现状
- 关注趋势
- 目标驱动
数据分析大致分为两类。一种是后验分析:无非是某个指标涨了/跌了,“某个指标”可以代入日活、留存率、流失率等。
原因分析两条路走:内部因素和外部因素,内部因素可能是版本迭代导致的功能缺失不可用、体验变差、统计错误或者推荐策略修改等等;
外部因素区分突发短暂的因素和长期潜移默化的因素,前者如突发新闻、节假日、发行改变、特别习俗等,后者可能是设备、网络、国家政策、头部网站的变化等等。
关注关键时间点,用排除法从广到窄层层收网找出差异点,提出大概率事件的假设。
另一种是先验分析,如拟降低无点击用户占比,分析无点击用户的行为特征和兴趣标签,这类分析根据不同业务有不同的侧重点。
数据分析过程强调1个思维2个指标(敲黑板,划重点了)。
1. 漏斗分析思维
漏斗思维在日常工作中很常见,运用漏斗分析的思维,便于环环监控,查漏补缺,对症下药。日常流量漏斗应用广:
推荐召回排序漏斗:
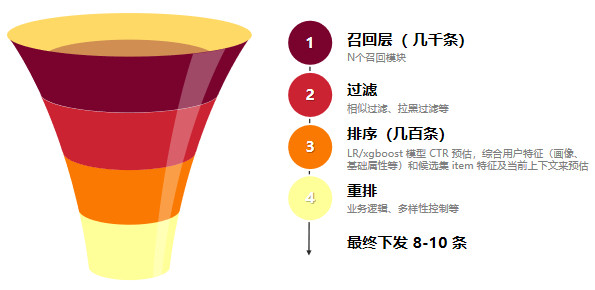
(以上数据仅做模型示意,不做实际参考)
打车软件漏斗模型:
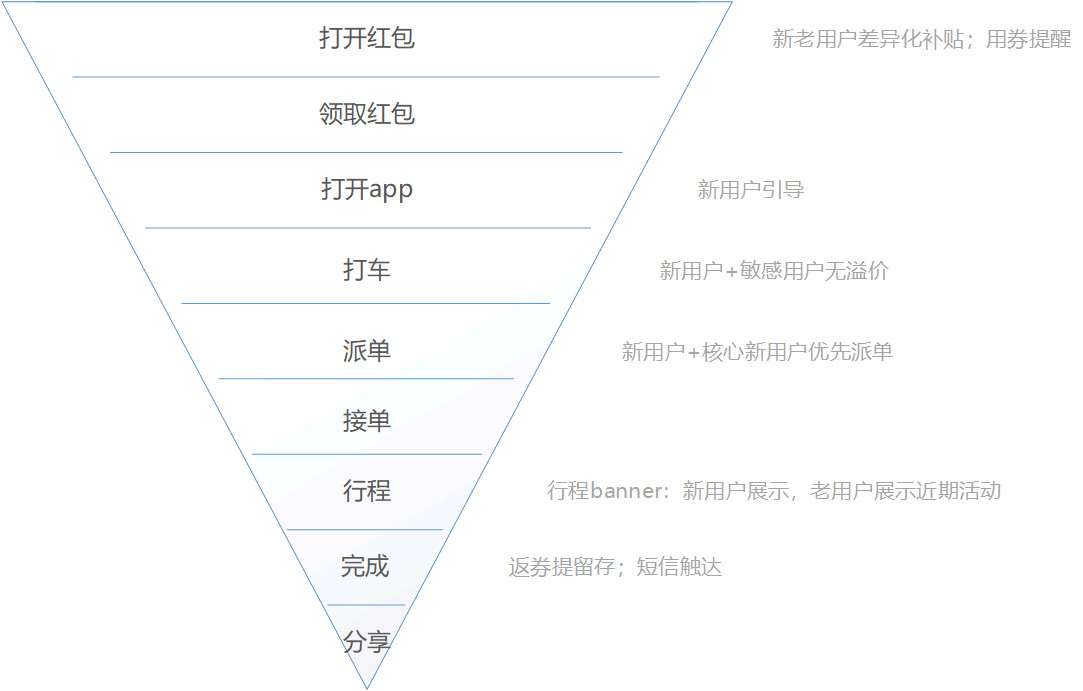
移动页面营销流量漏斗:
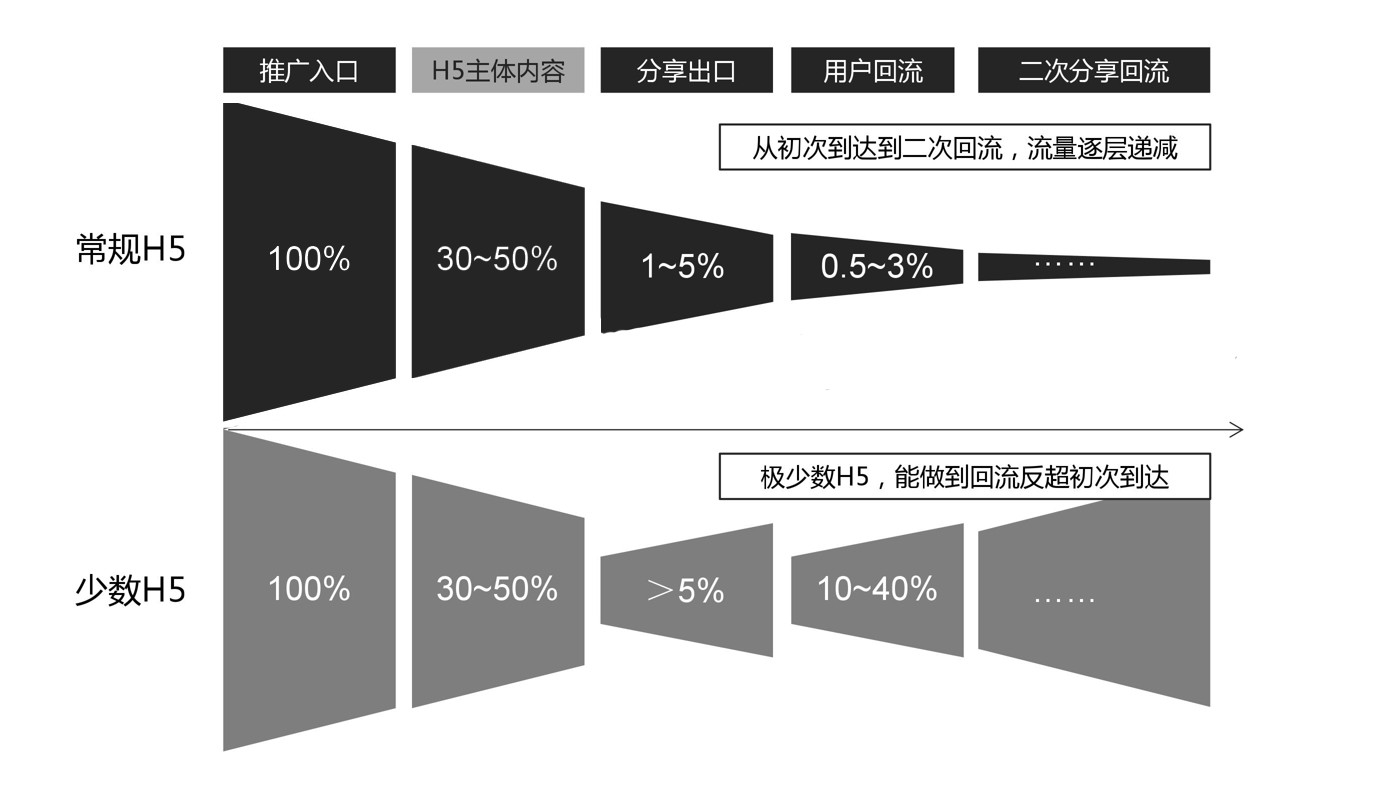
(以上数据仅做模型示意,不做实际参考)
以H5营销活动为例,以下是漏斗中各环节指标,逐级递减。

- 曝光:评估触达多少用户;
- 曝光点击率:评估物料优质程度;
- 成功加载率:loading环节会损失多少用户,判断是否存在性能问题;
- 各页面/按钮参与率:评估各互动环节设计是否合理,UI是否清晰明了等;
- 病毒传播系数:自传播的可能性,综合评估获客成本。
根据不同业务需求,以上指标还能细拆,如总访问中关注不同渠道的流量,如区分微信、微博、端内流量,方便评估渠道质量,按需投放。
2. 北斗星指标
即“在任何时候抬起头看,他都在你前进的道路上”。北斗星指标是让团队聚力,少走弯路的一个指导性指标(也是KPI完成度的依据),正因如此,制定一个正确的北斗星指标非常关键,因为他回答了现阶段最重要的问题。
如某服务供应商,有一个指标高于其他指标:净增加,这个指标有助于快速发现退订量高的日子并寻找问题;餐饮业关注前一天人工成本占毛收入的比例,为了得要一个优秀的数值,你不得不推进人均消费和人力成本。
产品发展的不同阶段会有不同北斗指标,但每个阶段关注一个北斗指标即可,不贪多。
3. 虚拟指标
虚拟1:注重PV、UV等“量级”类的指标,忽略转化率。
某图片网站的日均访问人数访问次数过百万,但同时跳出率也高达75%,实际留下消费的用户寥寥无几。
某新闻app某频道日均访问十几万,无刷新无点击用户占比85%,实际有消费的用户仅有几万。
这种注意力转移时常会变成写汇报的“故意”技巧,“转化不好量级来凑”。制定正确的数据指标,避开虚荣指标,数据指标之间的耦合现象也值得注意,例如转化率和购买所需时间,病毒传播系数和病毒传播周期。
虚拟2:相对值和绝对值,只选其一。
新上架的某工具类app,DAU增长500%,实质原始基数只有20人,增长500%即增长至120人
相对值和绝对值,避重就轻就是耍流氓。
虚拟3:关注某指标下的全量用户,忽略真实有意义的用户行为。
某买卖二手书app一开始关注每月卖家人数、上传商品数量、卖家人均上传商品数量,数据很漂亮;若以月为单位关注一个月内有活跃的商家、一周内有搜索曝光次数大于3次的商品数量,就会发现趋势并不乐观。
“有效行为”可能含义丰富,需要寻找有意义的用户行为模式和机遇,虚拟数据的噪音会掩盖原本你应该要面对和解决的问题。
除了1个思维2个指标,了解数据瓶颈(也称“天花板”)和同行大盘,能让你把精力和财力花在刀刃上。如,某CEO对8%的流失率心烦意乱,和同行沟通后发现8%已经是一个较低值,他便改变了关注点,“流失率维持即可,精力放在其他指标”。
三、数据采集
常见的数据采集有以下四个渠道:
- 行为数据(埋点)
- 流量数据(JS采集或第三方,如Google Analytics、百度统计)
- 业务数据(运营后台)
- 外部数据(第三方或爬虫)
to C的产品如腾讯新闻,产品汪最常接触的是行为埋点数据,埋点展开说是长篇幅的技术统计学(详见下一篇推送);品牌推广、H5营销PR常关注流量数据;关注订单成交的运营喵日常跑后台数据;竞品分析外部数据爬起来。
四、数据清洗
数据清洗根据不同的业务场景有不同的标准,主要是一些空值、异常值的处理,使数据得出的结论可靠可信。
栗子1:取非0数据时要排除null。
…… where click !=0 or click not null or ……
栗子2:统计时长(duration)相关行为时,过高或过低的时长为异常值,假定>=10 ms 和 <=10000000 ms 的阅读行为有效行为。
select date, itemid, count(itemid) as rec, sum(isexposure) as exposure, sum(case when duration>=10 and duration<10000000 then isread else 0 end) as click, sum(case when duration>=10 and duration<10000000 then duration else 0 end)/1000 as readtime from alluseractiveinfo ……
栗子3:记录用户点击历史时,排除停留时长<=1s的点击。
排除虚假点击,让记录的用户数据更贴近用户的真实意图,提高推荐策略的准确性。
其他
数据分析重在思维,可能有人会问“我需要学习获取数据、分析数据的工具技能吗”?
如果你在UC、腾讯这类大厂工作,一群兢兢业业的BI工程师会将苦涩难懂的数据可视化,你只要懂得提需求+善用“筛选”功能即可得到你想要的数据;
如果你在中小公司工作,Excel要玩得溜的同时,学点SQL和Python总没错,不然你可能会面临“取一个数据要排期一两周”的尴尬。
学习一些基础的工具技能,例如在Python尝试用pearsonr(x, y)分析各项指标的相关性,用SQL percentile(BIGINT col, p)引发对不同分位点的思考,对思维益处多多且效率提高不少(Skill:Excel->SQL->Python)。做一个数据驱动的产品汪,如获武林秘诀。
结语
Accenture的首席科学家肖尔·斯瓦米纳坦说:“科学是纯粹经验主义和不带偏见的,但是科学家不是。科学家是客观和机械的,但是科学家不是。科学是客观和机械的,但是它同样重视那些有创造力、直观思考、能够转变观念的科学家。”
注重数据善用数据的同时,避免唯数据论,毕竟它是验证直觉、提高效率少走弯路的手段而已。
在互联网+时代,“你的用户用每次点击、浏览、喜欢、分享和购买都会留下一条洒满数字面包屑的轨迹,这条轨迹从他们第一次听说你开始,到永远流失那天结束”。
突然觉得生活在这个时代从事着互联网工作(推荐产品+数据分析)很幸福,“熟悉的陌生人”的无声交流,让事情一点点变好,就暂且抛开数据泄露数据利用这种恼人的话题吧。
备注:部分引用来自[美]埃里克·莱斯 编著的《精益数据分析》,进阶级的数据分析推荐阅读。
本文由 @张小喵Miu 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: