关于数据埋点采集,你需要了解这些
数据采集是数据分析的基础,而埋点是最主要的采集方式。那么数据埋点采集到底都包括哪些问题?本文作者从什么是埋点、埋点怎么设计、埋点的应用三个方面对这个问题进行了梳理,与大家分享。

一、数据采集以及常见数据问题
1. 数据采集
数据采集有多种方式,埋点采集是其中非常重要的一部分,不论对c端还是b端产品都是主要的采集方式。
数据采集,顾名思义采集相应的数据,是整个数据流的起点,采集的全不全,对不对,直接决定数据的广度和质量,影响后续所有的环节。在数据采集有效性,完整性不好的公司,经常会有业务发现数据发生大幅度变化。
数据的处理,通常由以下5步构成:

2. 常见数据问题
大体知道数据采集及其架构之后,我们看看工作中遇到的问题,有多少是跟数据采集环节有关的:
- 数据和后台差距很大,数据不准确-统计口径不一样、埋点定义不一样、采集方式带来误差;
- 想用的时候,没有我想要的数据-没有提数据采集需求、埋点不正确不完整;
- 事件太多,不清楚含义-埋点设计的方式、埋点更新迭代的规则和维护;
- 分析数据不知道看哪些数据和指标-数据定义不清楚,缺乏分析思路。
我们需要根源性解决问题:把采集当成独立的研发业务来对待,而不是产品研发中的附属品
二、埋点是什么
1. 埋点是什么
所谓埋点,就是数据采集领域的术语。它的学名应该叫做事件追踪,对应的英文是Event Tracking 指的是针对特定用户行为或事件进行捕获,处理和发送的相关技术及其实施过程。
数据埋点是数据分析师,数据产品经理和数据运营,基于业务需求或者产品需求对用户行为的每一个事件对应位置进行开发埋点,并通过SDK上报埋点的数据结果,记录汇总数据后进行分析,推动产品优化和指导运营。
流程伴随着规范,通过定义我们看到,特定用户行为和事件是我们的采集重点,还需要处理和发送相关技术及实施过程;数据埋点是服务于产品,又来源于产品中,所以跟产品息息相关,埋点在于具体的实战过程,跟每个人对数据底层的理解程度有关。
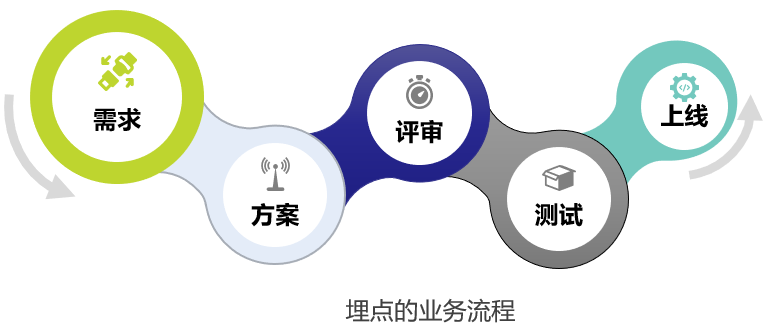
2. 为什么要做埋点
埋点就是为了对产品进行全方位的持续追踪,通过数据分析不断指导优化产品。数据埋点的质量直接影响到数据,产品,运营等质量。
- 数据驱动-埋点将分析的深度下钻到流量分布和流动层面,通过统计分析,对宏观指标进行深入剖析,发现指标背后的问题,洞察用户行为与提升价值之间的潜在关联;
- 产品优化-对产品来说,用户在产品里做了什么,停留多久,有什么异常都需要关注,这些问题都可以通过埋点的方式实现;
- 精细化运营-埋点可以贯彻整个产品的生命周期,流量质量和不同来源的分布,人群的行为特点和关系,洞察用户行为与提升业务价值之间的潜在关联。
3. 埋点的方式
埋点的方式都有哪些呢,当前大多数公司都是客户端,服务端相结合的方式:
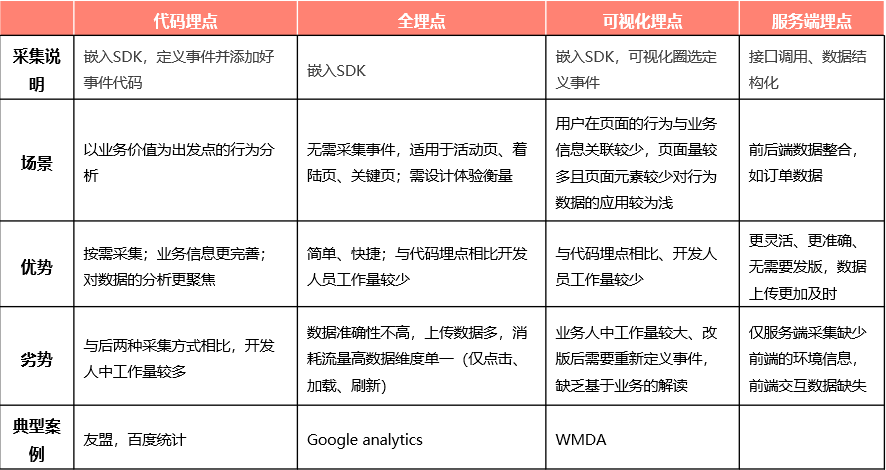
准确性:代码埋点 >可视化埋点>全埋点
三、埋点的框架和设计
1. 埋点采集的顶层设计
所谓的顶层设计就是想清楚怎么做埋点,用什么方式,上传机制是什么,具体怎么定义,具体怎么落地等等;我们遵循唯一性,可扩展性,一致性等的基础上,我们要设计一些通用字段及生成机制,比如:cid, idfa,idfv等。
- 用户识别: 用户识别机制的混乱会导致两个结果:一是数据不准确,比如UV数据对不上;二是涉及到漏斗分析环节出现异常。因此应该做到:a.严格规范ID的本身识别机制;b.跨平台用户识别;
- 同类抽象: 同类抽象包括事件抽象和属性抽象。事件抽象即浏览事件,点击事件的聚合;属性抽象,即多数复用的场景来进行合并,增加来源区分;
- 采集一致: 采集一致包括两点:一是跨平台页面命名一致,二是按钮命名一致;埋点的制定过程本身就是规范底层数据的过程,所以一致性是特别重要,只有这样才能真正的用起来;
- 渠道配置: 渠道主要指的是推广渠道,落地页,网页推广页面,APP推广页面等,这个落地页的配置要有统一规范和标准。
2. 埋点采集事件及属性设计
在设计属性和事件的时候,我们要知道哪些经常变,哪些不变,哪些是业务行为,哪些是基本属性。
基于基本属性事件,我们认为属性是必须采集项,只是属性里面的事件属性根据业务不同有所调整而已,因此,我们可以把埋点采集分为协议层和业务层埋点。
- 业务分解: 梳理确认业务流程、操作路径和不同细分场景、定义用户行为路径
- 分析指标: 对特定的事件进行定义、核心业务指标需要的数据
- 事件设计: APP启动,退出、页面浏览、事件曝光点击
- 属性设计: 用户属性、事件属性、对象属性、环境属性
3. 数据采集事件及属性设计
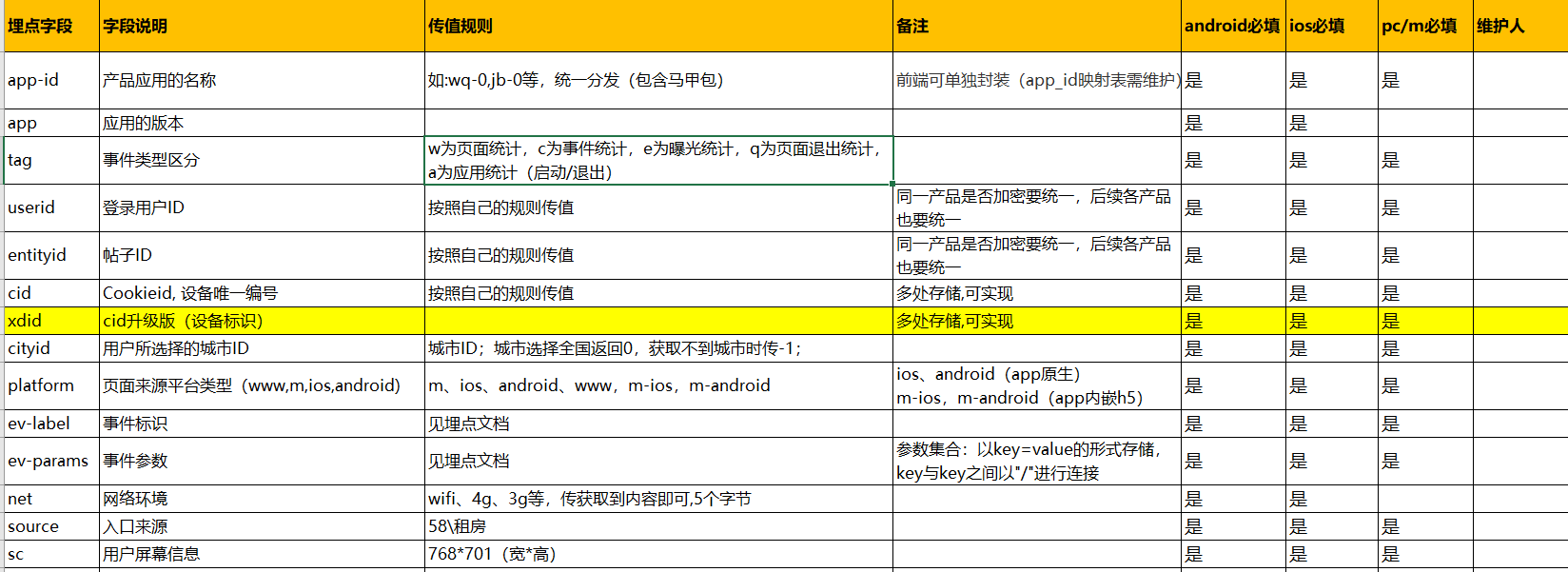
Ev事件的命名,也遵循一些规则,同一类功能在不同页面或位置出现时,按照功能名称命名,页面和位置在ev参数中进行区分。仅是按钮点击时,按照按钮名称命名。
ev事件格式:ev分为ev标识和ev参数
规则:
ev标识和ev参数之间用“#”连接(一级连接符);
ev参数和ev参数之间用“/”来连接(二级连接符);
ev参数使用key=value的结构,当一个key对应多个value值时,value1与value2之间用“,”连接(三级连接符);
当埋点仅有ev标识没有ev参数的时候,不需要带#;
备注:
ev标识:作为埋点的唯一标识,用来区分埋点的位置和属性,不可变,不可修改;
ev参数:埋点需要回传的参数,ev参数顺序可变,可修改;)
app埋点调整的时,ev标识不变,只修改后面的埋点参数(参数取值变化或者增加参数类型)
eg: 一般埋点文档中所包含的sheet名称以及作用:
A、曝光埋点汇总;
B、点击和浏览埋点汇总;
C、失效埋点汇总:一般会记录埋点失效版本或时间;
D、PC和M端页面埋点所对应的pageid;
E、各版本上线时间记录;
埋点文档中,所有包含的列名及功能:

4. 基于埋点的数据统计
用埋点统计数据怎么查找埋点ev事件:
- 明确埋点类型(点击/曝光/浏览)——筛选type字段
- 明确按钮埋点所属页面(页面或功能)——筛选功能模块字段
- 明确埋点事件名称——筛选名称字段
- 知道ev标识,可直接用ev来进行筛选
根据ev事件怎么进行查数统计:当查询按钮点击统计时,可直接用ev标识进行查询,当有所区分可限定埋点参数取值;因为ev参数的顺序不做要求可变,所以查询统计时,不能按照参数的顺序进行限定;
四、应用-数据流程的基础
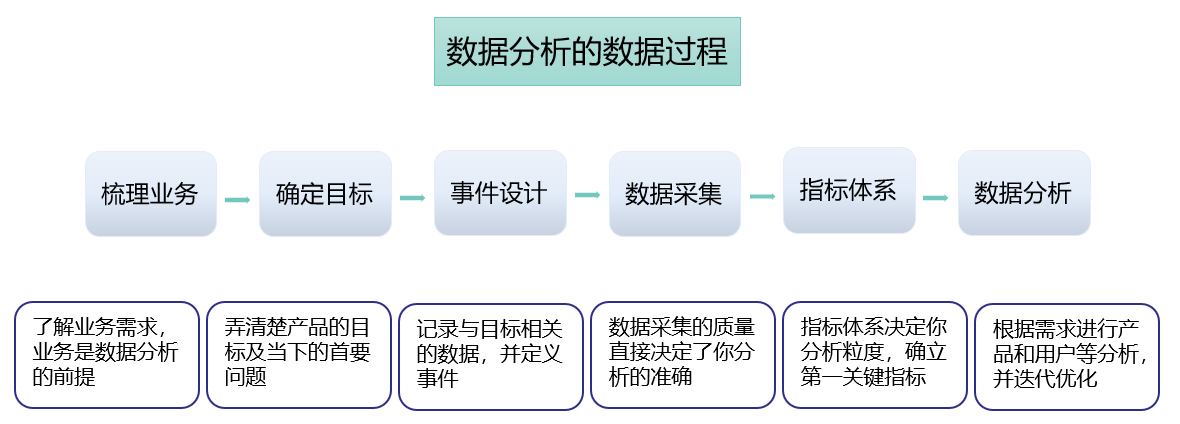
1. 指标体系
体系化的指标可以综合不同的指标不同的维度串联起来进行全面的分析,会更快的发现目前产品和业务流程存在的问题。

2. 可视化
人对图像信息的解释效率比文字更高,可视化对数据分析极为重要,利用数据可视化可以揭示出数据内在的错综复杂的关系。
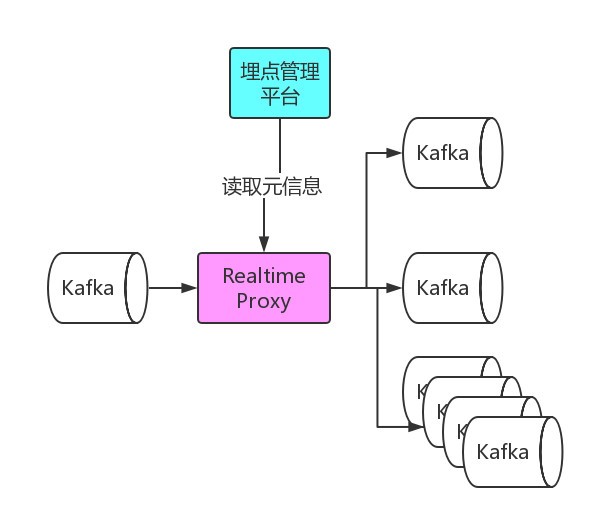
3. 埋点元信息api提供
数据采集服务会对采集到的埋点写入到 Kafka 中,对于各个业务的实时数据消费需求,我们为每个业务提供了单独的 Kafka,流量分发模块会定期读取埋点管理平台提供的元信息,将流量实时分发的各业务 Kafka 中。
数据采集犹如设计产品,不能过度,留出扩展余地,但要经常思考数据有没有,全不全,细不细,稳不稳,快不快。
作者:赵小洛,wechat:luoluo963,邮箱:youlu2409@163.com;公众号:赵小洛洛洛,欢迎关注我的微信公众号,给我留言数据相关话题。
本文由 @赵小洛 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: