德州扑克:AI打牌也能完胜人类了
笔者从完美信息博弈类游戏的理论出发, 分析了AI打德州扑克为何能打赢人类?

前段时间,受周围朋友的影响,喜欢上了德州扑克,享受和牌友心理博弈的过程,也享受“赌博”带来的快感。一直觉得德州最大的魅力就在于 它不完全是理性的判断,更多的是感性、勇气和理智之间的较量 ,不确定性太多,所以它区别于其他的棋牌类游戏,没有办法通过学习一些套路和技巧就能完胜对手。
最近回了学校,又开启了每天和AI“博弈”的磕盐生活。今天惊奇的发现, AI打德州扑克居然也完胜人类了 !此次比赛共持续 20 天,由 4 名人类职业玩家 Jason Les、Dong Kim、Daniel McAulay 和 Jimmy Chou 对战人工智能程序 Libratus,在为期 20 天的赛程里面对玩 12 万手,争夺 20 万美元的奖金。最终的结果是 「比赛过程中,人类选手整体上从未领先过」 。

随着天数的增加,AI和人类选手的差距愈发明显
近几年,随着科技的不断发展,计算机打败人类的案例屡见不鲜。作为一只“程序媛”,我也算是半个“局内人”,本科参与过一些计算机博弈和机器人相关的比赛,硕士期间对AI也有一些浅显的了解。今天就从理性的角度讲讲,AI是如何打败人类的。

几年前也是辉煌过的~~~
德州扑克怎么玩?(会玩请忽略)德州扑克是目前世界上最流行的扑克游戏。总结来说,如果想要赢牌, 第一种可能就是你的牌比其他人的牌都大,第二种可能就是通过押注的技巧把牌没有你大的对手都吓跑 。可能性就是德州扑克最有趣的地方。
图片来自网络,侵删
完美信息博弈和不完美信息博弈
为什么AI不容易在德州扑克上打败人类呢?德州扑克和围棋对AI来讲到底有什么区别?首先,要理解完美信息博弈(棋牌类游戏)和不完美信息博弈(扑克类游戏)的区别。
完美信息博弈是指后行动的参与者可以观测到先行动的参与者的行动信息。 像棋牌类游戏,双方的信息都是共享的,比如围棋,双方都能够看到场上已经下过的旗子以及双方的优势和劣势。
而扑克、谈判、商业决策等问题, 双方的信息都是不公开给对方的,也即是说但参与者做选择的时候不知道其他参与者的选择,这就被称谓不完美信息博弈 。
简单来说,如果把其他参与者的行动理解为一个参与者做决策时所面对的环境,信息不完美就是决策者不知道自己所处的决策环境。
对德州扑克,即使对手all in了所有的筹码,那么我们也不清楚他手里到底有什么底牌,信息的不对称,就迫使大家必须有“赌一把”的精神。
这也是为什么金融人士和投资大佬们都喜欢玩德州扑克。
我们用理工的思维讲讲AI是怎么赢了人类的——完美信息博弈类游戏
对于围棋游戏来说,是一场 零和完美信息博弈 ,这是指在任何时刻,双方玩家都知道前面游戏的全部状态(完美信息),并且在有限步数之后游戏的结果非胜即负(零和)。知道了游戏的有限状态,计算机就可以通过 暴力枚举 的方法来计算后面所有可能的下法,形成一颗巨大的搜索树,这颗搜索树可以列举出在当前状态下所有可能的下法,每个子搜索树都能独立求解,计算机就可以根据计算的结果安排对应的策略,从而达到最终的胜利。
举个栗子,比如,小明是一个普通中国家庭长大的小孩,在他的一生中,面临着很多个选择,如何才能在未来走向人生巅峰呢?如果可以列举出他未来所有的可能性,把每一步的选择拆解成“子未来”,那么就可以计算出成功胜算最大的选择了。 (例子可能不够恰当,理解意思就好,嘻嘻)
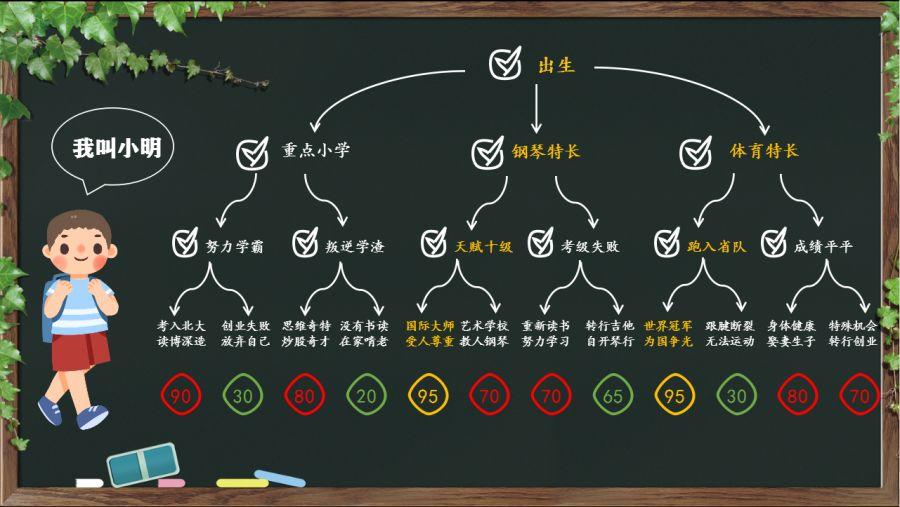
小明同学的人生探险
所以,假设我们有 无限大 的计算资源,就可以将一局游戏的博弈拆解成一个一个的子博弈(列举出所有的可能性),从而计算出胜算最大的打法,就可以打赢比赛了。
但是,以棋类游戏中比较简单的西洋棋来说,它的分支因子大概是40左右,这表示预测之后20步的动作需要计算40的20次方( 这是多大,就算是1GHz的处理器,也要计算3486528500050735年 ),请注意,这还是比较简单的西洋棋。

电脑:“我压力太大了,哇的一声炸开花”
所以,科学家们利用一些剪枝、搜索等算法以缩减计算范围,从而在有限的时间内找出最佳策略。
不完美信息博弈类游戏
终于讲到了今天的主角, 德州扑克 。
德州扑克就是很典型的 不完美信息博弈类游戏 ,它的策略设置中存在隐藏的信息。 这类模型也有大量的应用场景,比如谈判、拍卖等等。
不完美信息博弈不能如完美信息博弈那样通过分解而进行求解,因为一个子博弈的最佳策略可能依赖于其它尚未得到的子博弈的策略和输出。
换句话说, 我们无法通过预测到对方下注的多少从而猜测到对方手里的牌是什么,因为也许对方的牌并不好,但他通过下注欺骗你,让你选择弃牌
。所以,这件事对于 没心机的计算机 是相当困难的,对手第一手就all in了,但是他的牌到底好不好呢?
因此,当我看到AI在德州上也打败了人类,还些许有些小激动, maybe未来,机器人也可以具有女人的第六感了 。
那AI到底是如何打败人类的呢?
论文中提及和很多很难理解(其实自己也看不太懂,逃)的算法,为了方便理解,我们以一个简单的博弈模型来举例,试图理解聪明的AI。
我们来设计一个简单的游戏。
游戏玩家有A和B两人。A可以抛一次硬币,正反面都只有自己才可以看到,抛完后他有两个选择:①sell,卖掉硬币;②play,和B玩游戏。
① A选择了sell:
- if:硬币落在正面,A卖掉后得到五毛钱;
- else:硬币落在反面,A卖掉后输掉五毛钱。
②A选择了play:游戏继续,接下来由B来猜硬币是落在正面还是反面:
- if : B猜对了,A赔一元,B赚一元;
- else:B猜错了,A赚一元,B赔一元。
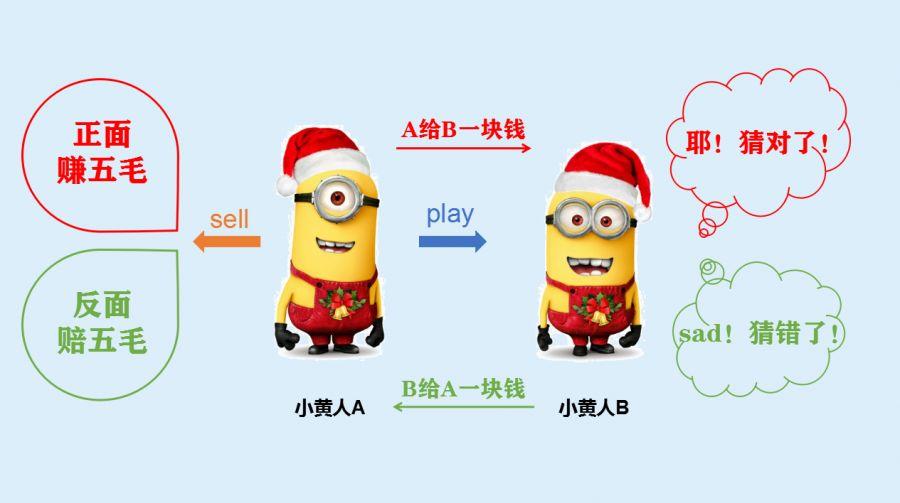
此时,对B而言, 就是一个不完美博弈,他无法从A选择play从而判断A手中的硬币是正面还是反面 。
这时有两个极限情况,如果 B总是猜正面 ,那么聪明的A就会变化策略,当他抛到正面时就卖掉硬币,如果抛到反面才玩游戏,这样B必然会输。此时,A的期望分数为:
0.5(抛到正面的概率)0.5(选择sell的得分)+0.5(抛到反面的概率)1(选择play的得分)=0.75
如果 B总是猜反面 ,那么A抛到正面时就会选择play,得一元;抛到反面就会选择sell卖掉硬币,这样只赔五毛钱。所以A的期望是:
0.5(抛到正面的概率)1(选择play的得分)+0.5(抛到反面的概率)(-0.5)(选择sell的得分)=0.25
此时,出现一个知识点,叫 纳什均衡 ,也就是 B为了有效的降低损失,他最有效的策略就是以0.25的概率猜正面,以0.75的概率猜反面 ,这样可以确保他的胜算最大。
而博弈永远是一个动态的过程,如果B持续按照固有的策略做决策,那么A也会根据B的决策结果调整自己的策略。所以, 对B最安全的方法,就是不断更新A卖掉硬币会得到的回报,持续寻找最优解 。
我们聪明的计算机就是通过这样的方法动态的计算牌友们押注所带来的回报期望,进而“ 持续更新对手的套路 ”,最终获得了 「比赛过程中,人类选手整体上从未领先过」 的效果。
看来,想要和AI斗智,人类的小脑筋maybe还需要转的更快才行嘞,也许没有套路才是最大的套路哦。
都说金融大佬都爱玩德州,看完这篇文章,金融大佬们是否有些启发呢?
本文由 @汪仔7199 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: