专访图灵奖得主Yoshua Bengio:AI能否有“意”为之?
编者按:本文来自微信公众号“Robinly”(ID:RobinlyChannel),作者Robinly,36氪经授权发布。

Bengio教授(右)与Robin.ly特邀主持人、MIT助理教授韩松(左)
Yoshua Bengio是世界级人工智能专家和深度学习“三巨头”之一,在2018年与Geoffrey Hinton和Yann LeCun共同获得图灵奖。现任蒙特利尔学习算法研究所(Mila)创始人和科学主任,蒙特利尔大学教授,迄今发表过300多篇学术文章,引用超过8万次。
Bengio在刚结束的NeurIPS 2019大会上发表题为“从系统1深度学习到系统2深度学习”的主题演讲,提出深度学习正在从直观的、无意识的静态数据集学习,向具有意识、推理和逻辑的新型架构研究转变。
Bengio在大会现场接受了Robin.ly特邀主持人、MIT的助理教授韩松的专访,深入讨论了具有“意识”的深度学习方向、再度兴起的“元学习”研究、以及AI模型训练的能源消耗问题,并针对目前AI领域的压力竞争环境给年轻研究者提出了恳切的建议。
1、因为信念,所以坚持
韩松:早上好 Yoshua,感谢您接受我们的采访!您已经在深度学习领域工作了数十年,能否与我们分享一下您在这些年的研究历程和经验?
Yoshua Bengio:
研究人员对自己的科研想法有着深厚的感情,我也一直对自己的研究充满热情。我很喜欢一个所谓的“精彩假设 (The Amazing Hypothesis)”,即可能存在一些简单的原理,能够解释我们的智能。我在1985 年左右开始阅读神经网络的相关论文,对Geoffrey Hinton研究组的论文印象最为深刻。我当时就决定要从事神经网络方向的研究,几十年来一直如此。

2018年Yoshua Bengio与Geoffrey Hinton和Yann LeCun共同获得图灵奖
在80年代后期,从事这方面研究的人还很少,但大家对神经网络的兴趣开始日渐浓厚。我在1991 年获得了博士学位,但随后的几年,随着其他机器学习方法的兴起,人们对神经网络的兴趣开始逐渐下降。
正是我对这些想法坚定的信念,支持我在很长一段时间持续从事这个方向的工作。同时,我还更多地了解了神经网络以及包括内核方法(Kernal method)在内的其他方法的局限性,从数学上更直观地肯定了我的直觉。
在过去十几年中,得益于成功的应用案例,深度学习方向的研究出现了爆炸式增长。它不仅成为大学中的一门科目,还产生了重要的社会和商业价值。在深度学习改变社会的过程中也可能会产生负面的结果,我们对此也应该肩负起责任。
2、从“注意力”到“意识”
韩松:昨天,您做了题为“从系统1深度学习到系统2深度学习”的精彩演讲,其中的核心内容是注意力模型和具有意识的深度学习。能否进一步分享一下您对这个问题的想法?
Yoshua Bengio:
有一个很有意思的现象,在许多科学社区,人们往往会避免谈及跟“意识”有关的概念。但是在过去的几十年中,神经科学家和认知科学家对“意识”的认识更加清晰了。目前,我们开始可以利用机器学习(尤其是深度学习)去研究神经网络架构和目标函数/框架来实现某些具有”意识”的功能。对我来说,最令人兴奋的是这些功能可能为人类提供进化优势。而这些功能也可以帮助我们提高人工智能技术。
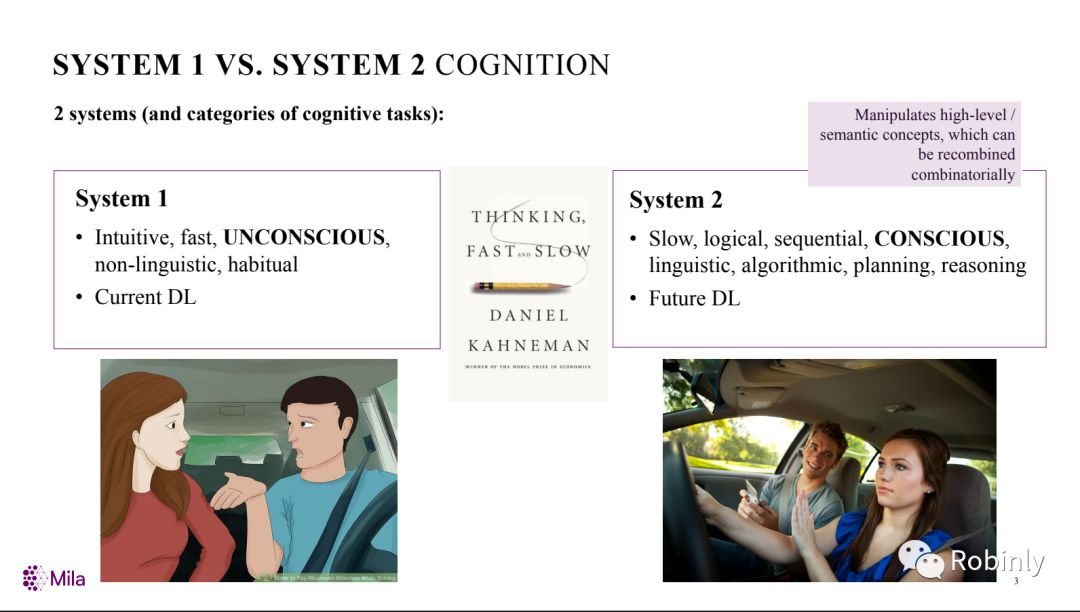
系统1深度学习与系统2深度学习比较,来源:Yoshua Bengio
韩松:对于“意识”与“注意力”之间的关系,是不是可以说,“注意力”是寻求从高维度无意识集合到低维度有意识集合的映射,从而实现更有效的泛化呢?
Yoshua Bengio:
你说的很对。根据我的理论,对于一次只选择几个变量的机制,你可以将其视为正则化函数(regularizer)和对世界的先验假设 (priori),人类可以利用这一假设形成我们能够用语言处理的高级概念。如果我说:“我扔出一颗球,它会掉在地上”,这句话只涉及很少的概念,注意力只会选择正确的词和概念,而且这些词彼此具有很强的依赖性。例如,我可以预测某些动作的结果,这也是该句子所陈述的内容,会给该事件的发生带来很高的可能性。在某种程度上,我们能够使用很少的信息和很少的变量对未来做出这样的预测,是非常了不起的。这种注意力机制可以对应于我们如何组织关于世界认知的假设,即关于知识表征和语言的假设。因此,我们用语言来处理的各种概念会与我们大脑中具有最高表征的概念相对应。
韩松:不仅是语言,就如您在最近发表的循环独立机制(Recurrent Independent Mechanism,RIM)文章中所展示的那样,强化学习也是如此。比如 Atari 游戏,它与传统的循环神经网络(RNN)相比,具有强大的泛化能力。
Yoshua Bengio:
是的。我认为对于学习机器(learning machine)而言,这种对意识的看法对于智能体(agent)尤其重要。智能体是指能够在某些环境中运行的个体,像人、动物和机器人。智能体面临的一个重要问题是周围的世界一直在发生变化,它们需要快速适应和理解这些变化。我在文章中提出“意识机制”可以通过对碎片化的知识进行动态重组来帮助这些智能体应对各种变化。我们在实验中也的确发现,这种具有意识的结构可以使我们能够泛化到比训练数据更长的序列。
韩松:这样我们也不再需要对数据进行随机排序操作(shuffle)。
Yoshua Bengio:
是的。实际上,当我们打乱数据时,其中包含的信息也被破坏了。比如数据中包含一个结构信息,在数据被随机排序后,那个结构就消失了,而这种结构跟收集信息的具体时间密切相关。可能在最开始,我们处于某种数据状态,然后发生了某种变化,数据就变得跟之前不一样了。当然,打乱数据可以让泛化变得更容易,但这实际上是一种偷懒的行为,因为在现实世界中,数据没有被打乱,下次的情况跟之前很可能大不相同。因此,我们要做的实际上应该是构建对这些改变具有鲁棒性的系统。这也是“元学习”的重要之处。
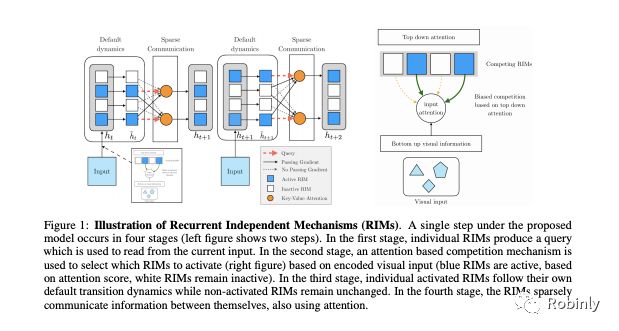
RIM模型,来源:Yoshua Bengio论文《Recurrent Independent Mechanisms》,论文链接:https://arxiv.org/abs/1909.10893
3、“元学习” 和“学会学习”
韩松:您在九几年发表过一篇关于”元学习 (Meta Learning)” 和“学会学习(learning to learn)”的论文。最近,随着“神经架构搜索”的普及,“元学习”再度成为热点。能否分享一下您对“元学习”的想法以及近几年的进展?
Yoshua Bengio:
最开始还没有“元学习”的概念,我们都把这个概念称作“学会学习”。我当时是受到生物体学习与进化之间关系的启发。用一个不太确切的对比,你可以把进化比作一种优化,因为不同物种通过进化能够把同样的事情做得越来越好。我们的外层循环就像缓慢的时间尺度一样,不断发展出越来越好的解决方案。同时,人在一生中,也会随着学习而进步,这就相当于在学习中学习。
我们在论文中展示了可以使用反向传播(back- propagation)工具来同时优化这两件事。最近几年,人们正在运用这些想法来优化学习体,不仅让它们在指定任务上做得更好,而且能够进行泛化,并对不同的变化和分布保持良好的鲁棒性。这些是使用一个假定分布进行正常训练的常规静态框架无法实现的。至少从理论上讲,元学习这个方法很重要。
韩松:我完全同意。另外,由于我们在“For Loop” 的外部又添加了“For Loop”,计算的复杂性已经变得非常高了。
Yoshua Bengio:
这就是为什么多年来这个领域一直不受欢迎。但是现在,我们具有比 90 年代初更强大的计算能力,有了GPU 和 TPU,我们也就可以开始实现通过“元学习”的方法从少量例子中学习。

Yoshua Bengio 1991年发表的“元学习”论文
(http://bengio.abracadoudou.com/publications/pdf/bengio1991ijcnn.pdf)
4、模型训练的碳足迹
韩松:我们注意到,目前的模型训练产生非常高的碳足迹。您也建了一个用于计算二氧化碳排放量的网站。您对这方面的环境问题有什么看法?
Yoshua Bengio:
生活中没有简单的事情,并且有许多重要的细节值得关注。机器学习可以用来应对气候变化这一重大的人类挑战。我们写过一篇很长的论文,解释了机器学习在气候科学中的许多应用, 比如设计更好的材料,提高用电效率,或者更好地利用可再生能源。
但与此同时,所有这些计算能力都潜在地汲取了更多来自不可再生能源的电力,造成了巨大的碳足迹。当然,这也取决于实验在哪里进行。比如在我居住的魁北克省,水力发电就是 100% 可再生的,不会产生碳足迹。但是如果在中国,可能会使用很多煤炭发电,那么情况就不一样了。
更令人担忧的是,学术界和工业界正在逐步建立越来越大的模型,每三个月就能翻一番,比摩尔定律还要快。因此,我们无法维持这种快速发展,最终这些 AI 系统会消耗掉地球上的所有电力。这并不是我们想要看到的。所以我们需要像你一样的人来帮助我们设计更加高效的系统。
你认为我们应该如何解决这个问题?
韩松:
我认为算法与硬件的协同设计对于解决这个挑战至关重要。以前,我们总是希望搭乘摩尔定律的顺风车来实现性能改进,期待计算机的运行速度一年比一年更快。随着摩尔定律的放缓,我们也开始试图通过改进算法来减少内存占用量。通常能源的消耗主要来自对内存的大量占用。
目前,我们已经取得了一些成功,例如我开发的深度压缩(Deep Compression )方法,可以通过高效的推理引擎来节省计算量,将模型缩小一个数量级,从而减少内存用量。近来,我们一直在努力降低Transformer的神经网络架构搜索成本。通常一个模型的碳成本相当于五辆汽车生命周期的碳足迹。
Yoshua Bengio:
这是另一个值得关注的问题。媒体上报道的那些巨大的碳足迹数字主要是由于在架构和超参数空间中进行超参数优化搜索造成的,这比训练单个网络贵 1000 倍。如果在学术界,没有足够强大的计算能力,就要依靠人脑来进行搜索,这样效率会高很多。而我们目前单纯依靠机器探索架构空间几乎相当于是在用蛮力,成本十分高昂。
韩松:
非常赞同。去年我刚加入麻省理工学院时,我们只有八个GPU的算力,学生无法进行神经网络架构搜索,只能将人类智能与机器智能相结合,以更低成本的方式进行搜索。
蒙特利尔学习算法研究所(MILA)关注气候变化项目,来源:MILA
5、给年轻研究人员的建议
韩松:
作为人工智能的先驱人物,您对年轻一代的研究人员有什么建议?
Yoshua Bengio:
在当前的人工智能和机器学习领域,研究人员和学生面临着很多竞争,他们压力很大,非常焦虑,这让我感到非常忧心。最好的科学研究并不是在这样的环境下产生的,而是应该通过长期细致的思考,集思广益,进行各种尝试,让自己的想法逐渐发展成熟。
目前的状况是大家都只关注下一个截止日期。这个截止日期过了,两三个月后又会有另一个截止日期。我认为这样的氛围对AI领域的发展非常不利,对研究人员的心理状态也会产生负面影响。
所以我的建议是退后一步,设立一些更远大的目标,思考更有挑战性的问题,而不是只盯着接下来几周或下一个截止日期前要做什么。在研究上,要跟随你的直觉,开放地与同行分享和探讨你的想法;创造积极的交流氛围,不要害怕别人窃取你的想法。无论从心理还是科学的角度来说,积极地、公开的交流可以提供更健康的科研氛围和更高的科学生产力。(完)
作者暂无likerid, 赞赏暂由本网站代持,当作者有likerid后会全部转账给作者(我们会尽力而为)。Tips: Until now, everytime you want to store your article, we will help you store it in Filecoin network. In the future, you can store it in Filecoin network using your own filecoin.
Support author:
Author's Filecoin address:
Or you can use Likecoin to support author: